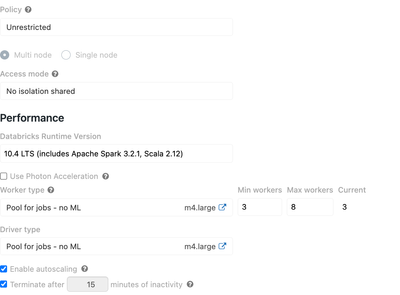
Hi @Vidula Khanna i have taken databricks data engineer associate exam on nov 27th . in result mail it is mentioned i have obtained below 70% in assessment but as per the section wise results i have gained more than 70% . Can you please check and up...
Process is to pickup data from an external table in Azure Synapse and combine with other tables and write to another synapse tables. Data for external table is in Azure storage. It was fine for months ,all of sudden last week it errored out with err...
Also do check out this blog from this stack overflow question.https://stackoverflow.com/questions/66747544/databricks-write-back-to-azure-synapse-errorhttps://chinnychukwudozie.com/2020/11/13/write-data-from-azure-databricks-to-azure-synapse-analytic...
I have created a workspace with private endpoint in Azure following this guide:https://learn.microsoft.com/en-us/azure/databricks/administration-guide/cloud-configurations/azure/private-linkOnce I have created the private link of type browser_authent...
Hello. I am trying to establish a connection between DBeaver and Databricks. I followed the steps in DBeaver integration with Databricks | Databricks on AWS, but I get the following error while testing the connection: Could anyone provide any insight...
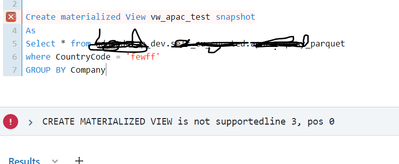
Hi Team,I was going through one of the videos of Databricks Sql Serverless and it say there is materialized view support . We can create materialized view .I tried same on my cluster of Sql Warehouse gives below error:
Materialized views is in private preview right now afaik. Please talk to your account or customer success team at Databricks in order to sign up and enable it for your workspace. Thanks!
I'm working on Databricks ACL enabled clusters, and having trouble performing dynamic partition overwrite to Delta tables.I have created a test table using the following query:CREATE TABLE IF NOT EXISTS test_01 (
id STRING,
name STRING,
c...
@Gustavo Amadoz Navarro Updated new infoThis course will be part of the data engineer learning path once the Databricks Certified Data Engineer Associate V3 exam is released (November 19, 2022). BEFORE YOU GET STARTED: Please note that this course,...
Hi @Yogita Chavan Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks
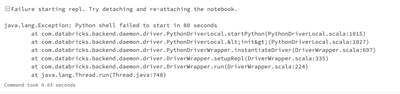
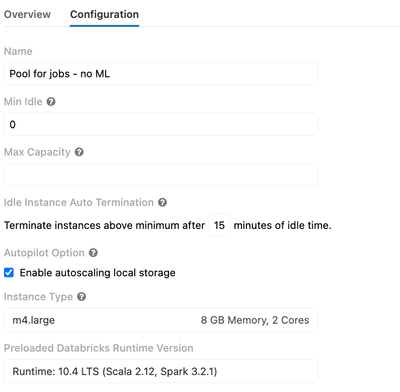
Today, we start working on setting up an all-purpose cluster pool for all the jobs that we are running on databricks. We used the documentation for this but we got some issues when running our jobs.The errors in the jobs are the following: The jobs a...
Hi @Siebert Looije Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
Hello,Is it possible to use a SFTP location to load from for structured streaming.At the moment we are going from SFTP->S3->databricks via structured streaming. I would like to cut out the S3 part.CheersChris
Hi @Chris Lant Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks.
I have filled the form to enable SQL Serverless twice in our Azure Databricks workspace, but I have not received any response through email nor I have serverless enabled in our workspace.
Hi @Manuel Torrez Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
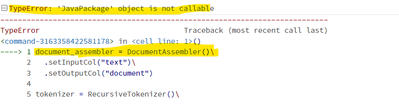
Hi,I am doing a grammar check using spark NLP using azure databricks. But am getting TypeError: 'JavaPackage' object is not callable - in DocumentAssembler() intialization line.document_assembler = DocumentAssembler()\ .setInputCol("text")\ .setOutpu...
Hi its working after adding below configs in cluster. Please check URL for more info :- https://nlp.johnsnowlabs.com/docs/en/install#databricks-support
Hi ive cleared Databricks Lakehouse Fundamental on 10/26/2022 and the certificate i received after clicking "download your certificate here" is not accurate as it only shows my name,i've also checked with accredible site. Please help me on this matte...
Hi @Srikrishna Parthasarathy Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear fr...
Hi @Jose Gonzalez i have taken databricks data engineer associate exam on nov 27th . in result mail it is mentioned i have obtained below 70% in assessment but as per the section wise results i have gained more than 70% . Can you please check and u...
I am attempting to run larger sql scripts through Databricks Notbook and export data to a file. For the most part the Notebook works when the sql script is a single SELECT statement. However, if the sql file is more complicated such as involving the ...
Hi @Marco Perez Does @Jose Gonzalez response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!