Hey there Community!! I have a client that will produce a CSV file daily that needs to be moved from Bronze -> Silver. Unfortunately, this source file will always be a full set of data....not incremental. I was thinking of using AutoLoader/cloudFil...
I "up voted'" all of @werners suggestions b/c they are all very valid ways of addressing my need (the true power/flexibility of the Databricks UDAP!!!). However, turns out I'm going to end up getting incremental data afterall :). So now the flow wi...
We are investigating how to pass parameter from Databricks Job to DLT pipeline. Our process orchestrator is Azure Data Factory from where we trigger the Databricks Job using Jobs API. As part of the 'run-now' request, we would like to pass a paramete...
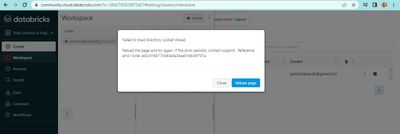
Hi,I am getting an error while creating a cluster and trying to open a notebook to run. How to overcome this error ? I have sent an email to databricks support but not received any response till now. Please help and guide.
I have a yaml file inside one of the sub dir in Databricks, I have appended the repo path to sys. Still I can't access this file. https://docs.databricks.com/_static/notebooks/files-in-repos.html
Hey everyone! I'm building a DLT pipeline that reads files from S3 (or tries to) and then writes them into different directories in my s3 bucket. The problem is I usually access S3 with an instance profile attached to a cluster, but DLT does not give...
I have a folder with multiples excel files that contains information from different cost centers, these files get update every week , im trying to upload all these files to the DB notebook , is there a way to connect the path directly to the DBFS to...
Hello, Thanks for your question.You can mount a cloud object storage to dbfs and use them in a notebook. Please refer here.It is not possible to mount a local folder from desktop to dbfs. But you should be able to use the Databricks CLI to copy the e...
Hi, i'm trying to run the notebooks but it doesn't do any activity.I had to create a cluster in order to start my code.pressing the play button inside of notebook does nothing at all.and the 'compute' , pressing play there on the clusters gives the e...
Hi @Ghazanfar Uruj,Just a friendly follow-up. Did any of the responses help you to resolve your question? if it did, please mark it as best. Otherwise, please let us know if you still need help.
Hi @Stephanie Rivera,Just a friendly follow-up. Did any of the responses help you to resolve your question? if it did, please mark it as best. Otherwise, please let us know if you still need help.
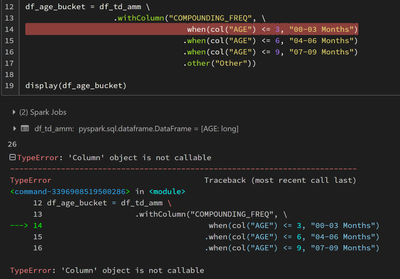
The very first "when" function results in the posted error message (see image). The print statement of the count of df_td_amm works. A printSchema of the "df_td_amm" data frame confirms that "AGE" is a column. A select statement is also successful, s...
On Jobs REST API is possible to create a new Job, specifying a git_source.My question is about triggering the job.Still on Jobs REST Api is possible to trigger a job using the job_id, but I don't find a way to tell anyhow to Databricks, what's the en...
I'm trying to save the returned json data from a requests API call to a Delta Table. I get a ParseError when I INSERT the response object which is in json format. The error shows the json data and a marker that states a ' or } or ) is missing. I v...
I have a list of jobs that are using the code in GitHub as source.Everything worked fine until yesterday. Yesterday, I noticed that all the job that were using GitHub as source were failing. Because of the following error: ``` Run result unavailable:...
Just an update, to round this out. We investigated further internally, and found that although we have a cleanup process in place to remove the internal repos that are being checked out for workflows, it was failing to catch up due to the sheer volum...
I would need to use the Job REST API to create a Job on our databrick Cluster.At the Job Creation, is possible to specify an existing cluster, or, create a new one.I can forward alot of information to the Cluster, but what I would like to specify is ...
@Antonio Davide Cali You can use the existing cluster in your json to use it for the job.To update or push libraries to the job, you can use the JobsUpdate API. As you want to push libraries to the cluster, you can push them using the new setting an...
Currently, I am facing an issue since the `databricks-connect` runtime on our cluster was updated to 10.4. Since then, I cannot load the jars for spark-avro anymore. By Running the following code from pyspark.sql import SparkSession
spark = SparkSe...