I'm tired of telling clients or referrals I don't know databricks but it seems like the only option is to have a big AWS account and then use databricks on that data. Can I download it locally for training, upskilling with python or is it only for cl...
Hi @Andrew Schell, We haven't heard from you on the last response from @Hubert Dudek , and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please share it with the community as it can be helpful to other...
We've had a qustion regarding possibly unexpected behaviour when creating multiple accounts on the account-level on https://accounts.cloud.databricks.com/.Short Version:It's possible to create multiple accounts with different letter-cases on https://...
Hello, I'm trying to read a table that is located on Postgreqsl and contains 28 million rows. I have the following result:"SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in sta...
Hi @Boumaza nadia ,Did you check the executor 3 logs when the cluster was active? if you get this error message again, I will highly recommend to check the executor's logs to be sure on what was the cause of the issue.
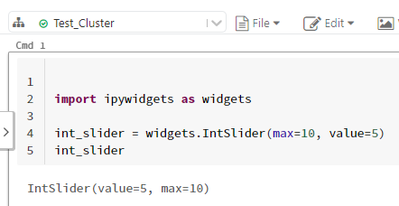
I'm looking forward to using ipywidgets which should be working in DBR 11.0 as they provide more options when creating a notebook UI. I saw that DBR 11.0 is available as of yesterday so I created a test cluster in the Databricks Community Edition ju...
Hi @Wayne Deleersnyder I was able to import ipywidgets in DBR 11.0. As you can see in the output below. The slider is visibleYou are facing this issue probably because the community edition has limited access. To get all the features you should at l...
Thanks for your kind reply:Below works for me:https://imgur.com/BmMzatIBut why, as you mentioned, using the classic path, below does not work?https://imgur.com/Ba1a4Iv
As per security concern, need to restrict/block the dbricks workspace url outside the corporate network. Tried below ip access list, it able to restrict only user login access out the corporate network but still the workspace id url is live outside t...
Hi @as999 Hope everything is going great!Does @Atanu Sarkar's response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly? Else please let us know if you need more help. We'...
I've tried this, but it doesn't appear to be working: https://community.databricks.com/s/question/0D53f00001GHVX1CAP/unable-to-install-sf-and-rgeos-r-packages-on-the-clusterWhen I run the following after that init script, I receive an error.library(r...
Hey there @Christopher Flach Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear fr...
Hi everyone, I have connected to Cosmos using this tutorial https://github.com/Azure/azure-sdk-for-java/tree/main/sdk/cosmos/azure-cosmos-spark_3_2-12/Samples/DatabricksLiveContainerMigrationAfter creating a table using a simple SQL command:CREATE TA...
Hey there @Joel iemma Hope all is well! Just wanted to check in if you would be happy to mark an answer as best for us, please? It would be really helpful for the other members too.Cheers!
Hi All, I think I might be missing something in regard to No Pubic IP Clusters. I have set this option on a workspace (Azure) and setup the appropriate subnets. To my surprise, when I went to setup a JDBC connection to the cluster the JDBC connec...
Hey there @Ashley Betts Hope you are well. Just wanted to see if you were able to find an answer to your question and would you like to mark an answer as best? It would be really helpful for the other members too.Cheers!
Hi there,I was wondering if I could get your advise.We would like to create a bronze delta table using GZ JSON data stored in S3 but each time we attempt to read and write it our clusters CPU spikes to 100%. We are not doing any transformations but s...
Hi Kaniz,Thanks for the note and thank you everyone for the suggestions and help. @Joseph Kambourakis I aded your suggestion to our load but I did not see any change in how our data loads or the time it takes to load data. I've done some additional ...
Current state:Data is stored in MongoDB Atlas which is used extensively by all servicesData lake is hosted in same AWS region and connected to MongoDB over private link Requirements:Streaming pipelines that continuously ingest, transform/analyze and ...
Hi @Alex Michel , We haven’t heard from you on the last response from the community members, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others. Ot...
Using VS code for development and a wheel package is created for shipment.We put this wheel package in Azure data lake storage and ADB notebook accessed this wheel package and installed it in the cluster. It is working fine. But instead of keeping th...
Hi @Thushar R, We haven’t heard from you on the last response from me , and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please do share that with the community as it can be helpful to others.
Why is it that certain Python visualisation libraries do not work on Databricks? I am trying to install (via pip) and work with some data visualisation libraries - they work perfectly in a normal Jupyter Notebook but not on a Databricks notebook envi...
How can we alter table with auto increment column for a delta tableI have tried this but not working:ALTER TABLE dbgtpTest.student ADD COLUMN Student_Id identity(100,1)any Suggestions will be helpful