I couldn't find it clearly explained anywhere, so hope sb here shed some light on that.Few questions:1) Where does delta tables are stored? Docs say: "Delta Lake uses versioned Parquet files to store your data in your cloud storage"So where exactly i...
Hello,My team is currently working on azure databricks with a mid sized repo. When we wish to import pyspark functions and classes from other notebooks we currently use %run <relpath>which is less than ideal.I would like to replicate the functionalit...
Hi @Sebastian Gay , This section guides developing notebooks and jobs in Azure Databricks using Python. The first subsection provides links to tutorials for common workflows and tasks. The second subsection provides links to APIs, libraries, and cri...
Running Pyspark script getting the following error depending on which xml I query:cannot resolve 'explode(...)' due to data type mismatchThe pyspark code:from pyspark.sql import SparkSession
JOB_NAME = "Complex file to delimeted files transformer"
...
Hi @Kevin Xu, Can you share the script where you have used the "explode" function?NOTE: Explode does not apply on string column. If you do this then error will come.
We offer the best web hosting solutions that are blazing fast, and ultra reliable & our sales & support team is here to help you find the right solutions
Hi, I wondered if some of you have had this issue before and how it can be solved. In a Databricks Job, we have a UBQ with a Painless script for ES. these are the options. Staging and prod are the same configurations, but Staging is failing with the ...
I am trying to something like this but getting error like :Error in SQL statement: AnalysisException: Undefined function: 'DATEADD'. This function is neither a registered temporary function nor a permanent function registered in the database 'default...
Dateadd was added in DBR 10.4 and is in DBSQL current.SELECT DATEADD(HOUR,IFNULL(100, 0),current_date) AS Date_Created_Local=> 2022-05-31T04:00:00.000+0000.You can also use one of these casts to turn any wellformed string into an interval:SELECT curr...
Hi everyone, I recently upgraded the runtime version of one of the databricks job to 10.4 LTS but Pattern Matching is not working as expected the same code is working in 7.3 LTS.Basically doing this and returning Left or Right: val result = spark.sql...
Hi, I'm listening to a stream for kinesis, don't need the data in real-time, so I could run it on an hourly basis looking to achieve two things:-Save money by don't have a cluster up 24/7-Have bigger files saved for each readThe stream is constant so...
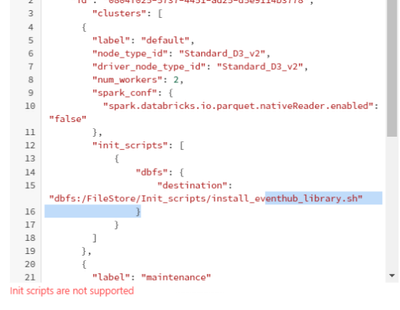
Hello,I would like to integrate Databricks Delta Live Tables with Eventhub, but i cannot install com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.17 on delta live cluster.I tried installed in using Init script (by adding it in Json cluster settings...
The last Databricks Light runtime release was 2.4 Extended Support. There was no Light version for Spark 3.x. Is Databricks Light runtime discontinued? If not, when we can expect the next DBR Light version?
Hi @Venkadeshwaran K, I looked around, and it does look like there won't be future light runtimes. We can't hire enough engineers to maintain and develop everything, and light is one of the casualties of that.
Startup Names is the place to find best brand names for sale completed with logo. Use our free business name generator for industry wise creative brand names.
Hi,I'm new to databricks but am positively surprised by the product. We use databricks delta tables as source to build a tabular model, which will serve as data source for Power Bi. To develop our tabular model we use Visual studio to import tables ...
Hi @geert vanhove , Just a friendly follow-up. Do you still need help, or have you resolved your problem with the above solutions? Please let us know.