Hey guys, I'm trying to find what are the options we can pass to spark_conf.spark.databricks.cluster.profileI know looking around that some of the available configs are singleNode and serverless, but there are others?Where is the documentation of it?...
Hi @LeoGaller , The spark_conf.spark.databricks.cluster.profile configuration in Databricks allows you to specify the profile for a cluster.
Let’s explore the available options and where you can find the documentation.
Available Profiles:
Sing...
Hey Everyone,I've built a very simple pipeline with a single DLT using auto ingest, and it works, provided I don't specify the output location. When I build the same pipeline but set UC as the output location, it fails when setting up S3 notification...
Hey @Babu_Krishnan I was! I had to reach out to my Databricks support engineer directly and the resolution was to add "cloudfiles.awsAccessKey" and "cloudfiles.awsSecretKey" to the params as in the screenshot below (apologies, i don't know why the sc...
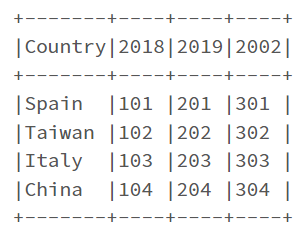
I am trying to unpivot a PySpark DataFrame, but I don't get the correct results.Sample dataset:# Prepare Data
data = [("Spain", 101, 201, 301), \
("Taiwan", 102, 202, 302), \
("Italy", 103, 203, 303), \
("China", 104, 204, 304...
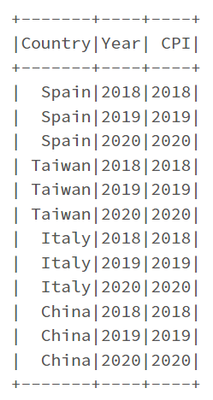
You can also use backticks around the column names that would otherwise be recognised as numbers.from pyspark.sql import functions as F
unpivotExpr = "stack(3, '2018', `2018`, '2019', `2019`, '2020', `2020`) as (Year, CPI)"
unPivotDF = df.select("C...
May be I am new to Databricks that's why I have confusion.Suppose I have worker memory of 64gb in Databricks job max 12 nodes...and my job is failing due to Executor Lost due to 137 (OOM if found on internet).So, to fix this I need to increase execut...
Hello @amitkmaurya ,
Increasing compute resources may not always be the best strategy. To gain more insights into each executor's memory usage, check the cluster metrics tab and Spark UI for your cluster. If one executor has a much higher memory usag...
Hi Team,Recently we had created new Databricks project/solution (based on Medallion architecture) having Bronze-Silver-Gold Layer based tables. So we have created Delta-Live-Table based pipeline for Bronze-Layer implementation. Source files are Parqu...
Hello @Devsql ,
It appears that you are creating DLT bronze tables using a standard spark.read operation. This may explain why the DLT table doesn't include "new files" during a REFRESH operation.
For incremental ingestion of bronze layer data into y...
I deleted for mistake some records from a streaming table, and of course, the streaming job stopped working. So I restored the table at the version before the delete was done, and attempted to restart the job using the startingVersion to the new vers...
Hello @6502,
It appears you've used the `startingVersion` parameter in your streaming query, which causes the stream to begin processing data from the version prior to the DELETE operation version. However, the DELETE operation will still be processe...
Hi,I have one table that changes the name every 60 days. The name simple increases the number version, for example:* Firtst 60 days: table_name_v1. After 60 days: table_name_v2 and so on.What i want is to query the table wich name returned in the que...
The simpliest way would be propably using spark.sql%py
tbl_name = 'table_v1'
df = spark.sql(f'select * from {tbl_name}')
display(df) From there, You can simply create temporary view:%py
df.createOrReplaceTempView('table_act')and query it using SQL st...
from pyspark.sql import functions as F
from pyspark.sql import types as T
from pyspark.sql import DataFrame, Column
from pyspark.sql.types import Row
import dlt
S3_PATH = 's3://datalake-lab/XXXXX/'
S3_SCHEMA = 's3://datalake-lab/XXXXX/schemas/'
...
I am going to use the newly released DLT with UC.But it keeps getting access denied. As I keep tracking the reasons, it seems that an account. ID other than my account ID or Databricks account ID is being requested.I cannot use '*' in principal attri...
Every service on AWS, an SQS queue, and all the other services in your stack using that queue will be configured with minimal permissions, leading to access issues. So, make sure you get your IAM policies set up correctly before deploying to producti...
When running my notebook using personal compute with instance profile I am indeed able to readStream from kinesis. But adding it as a DLT with UC, while specifying the same instance-profile in the DLT pipeline setting - causes a "MissingAuthenticatio...
This documentation https://api-docs.databricks.com/python/pyspark/latest/pyspark.sql/api/pyspark.sql.SparkSession.sql.html#pyspark.sql.SparkSession.sql claims that spark.sql() should be able to take kwargs, such that the following should work:display...
Ok, it looks like Databricks might have broken this functionality shortly after it came out: https://community.databricks.com/t5/data-engineering/parameterized-spark-sql-not-working/m-p/57969/highlight/true#M30972
I am trying to schedule some jobs using workflows and leveraging dynamic variables. One caveat is that when I try to use {{job.start_time.[iso_date]}} it seems to be defaulted to UTC, is there a way to change it?
Hi, all the dynamic values are in UTC (documentation).
Maybe you can use the code like the one presented below + pass the variables between tasks (see Share information between tasks in a Databricks job) ?
%python
from datetime import datetime, timed...
I want to cast the data type of a column "X" in a table "A" where column "ID" is defined as GENERATED ALWAYS AS IDENTITY. Databricks refer to overwrite to achieve this: https://docs.databricks.com/delta/update-schema.htmlThe following operation:(spar...
Hi,I am migrating from dbx to databricks asset bundles. Previously with dbx I could work on different features in separate branches and launch jobs without issue of one job overwritting the other. Now with databricks asset bundles it seems like I can...
Any updates here?My team is migrating from dbx to DABs and we are running into the same issue. Ideally, we would like to deploy multiple, parametrized jobs from a single bundle. If this is not possible, we have to keep dbx.Thank you!
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...