Hello everybody, I'm starting a cluster with a docker image because I my team use a lot of R libraries that would be time consuming to install them on a init script. The thing is that the cluster starts ok, but I can't acces to the cluster terminal a...
Hi @Francesco Camussoni , This is one of the limitations of DBR.Limitations of DBR:- Azure Databricks does not support running Spark jobs from the web terminal. In addition, the Azure Databricks web terminal is not available in the following cluster...
Hi Guys,Can someone point me to libraries to parse XML files in Databricks using Python / Scala.Any link to blog / documentations will be helpful.Looked into https://docs.databricks.com/data/data-sources/xml.html.Want to parse XSD's, seem this is exp...
Hi @Sreedhar Vengala , Please find attached the link related to XML Data Source for Apache Spark. Let me know if it helps.https://github.com/databricks/spark-xmlYou'll find these things in the above provided link - A library for parsing and querying...
Databricks CommunityNew to Databricks and work in R code. I have a data from with a date field that is a chr string and need to convert to a date field. Tried the standard as.Date(x, format = "%Y-%m-%d") , then tried the dplyr::mutate function and th...
I have hire_date and term_dates in the "MM/dd/YYYY" format in underneath csv files. Schema hint "cloudFiles.schemaHints" : "Hire_Date Date,Term_Date Date" - push data into _rescued_data column due to conversion failure. I am looking out solution to c...
I am trying to connect to our Databricks SQL endpoint using PHP in a Docker container.I setup my Docker container to download and configure the ODBC driver as specified here: https://docs.databricks.com/integrations/bi/jdbc-odbc-bi.html#install-and-c...
The problem was that the Databricks SQL driver does not yet support ARM, which my laptop and Docker container was building for. See ('01000', "[01000] [unixODBC][Driver Manager]Can't open lib '/opt/simba/spark/lib/64/libsparkodbc_sb64.so' : file not ...
Ignite your senses with distinctive and Fm World Shop delightful fragrances for your home, Discover scents to set the mood and inspire fragrant memories
Welcome to <a href="https://newstyleinteriors.com/">New Style Interior</a>. We offer high quality interior design and fit-out solutions for homes, offices, retail, commercial and event spaces.Our team of experienced and passionate designers combine c...
For stability, I've stuck with LTS. Last Friday my containers stopped working with error message:Py4JException: An exception was raised by the Python Proxy. Return Message: Traceback (most recent call last):
File "/databricks/spark/python/lib/py4j-...
This is getting worse. Now JDBC write to SQL is failing for same reason. I haven't yet found a solution for this.Am I not supposed to use containers? Python?This is not cool.
Hi We have to convert transformed dataframe to json format. So we used write and json format on top of final dataframe to convert it to json. But when we validating the output json its not in proper json format.Could you please provide your suggestio...
@Anand Ladda @André Monteiro From comments in the code:Indicates whether the task should be run in a REPL. This value must be true to run on an existing cluster. Please ignore the 'run_as_repl' parameters it will be removed from public docs as it i...
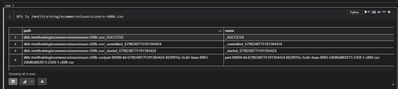
I tried to use %fs head to print the contents of a CSV file used in a training%fs head "/mnt/path/file.csv"but got an error saying cannot head a directory!?Then I did %fs ls on the same CSV file and got a list of 4 files under a directory named as a ...
Amritsar Digital Academy is the best https://www.amritsardigitalacademy.in/ digital marketing institute In Punjab. if you want to do a digital marketing course. you can enroll now!
Hello All, I am trying to use Databricks SQL but somehow the SQL end point is not getting started. It is in starting state for long time and then session is getting expired. Please note , the default SQL End point also not getting started. I am using...
@AMZ DUD did you get this working? With a quota of 500, 43 mins is a long time for a cluster to launch. Perhaps a something in the account isn’t set up correctly. Can you please email me your workspace ID please at bilal dot aslam at databricks dot ...