Hi @Vamsee krishna kanth Arcot Yes, currently you will have to download the JDBC from https://databricks.com/spark/jdbc-drivers-download and connect from other applications with JDBC URL just like you mentioned in your example. There is an internal ...
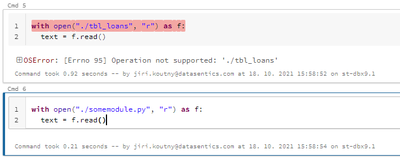
Hi @Jiri Koutny these files anyway should be synced to your remote repository (git, bitbucket, GitLab etc). The APIs from version control tools Git API for example might help you achieve what you want. https://stackoverflow.com/questions/38491722/r...
Hi @Nathan Tong You can go through the 2 articles below that I found online for Debugging in Databricks.1. 7 Tips to Debug Apache Spark Code Faster with Databricks 2. Easier Spark Code Debugging
Hi,I am new on the Databricks platform, few weeks before I created a community version and it was working perfectly till 2 days before, now I can not create a cluster anymore, after few minutes it time out whenever I am trying to create a new cluster...
Hi @Ashwinkumar Jayakumar and @Prabakar Ammeappin , I am facing the same issue for 3-4 days.Is there something wrong with Community Edition right now or does my account facing some issues?
Basically all what is needed is to create api token in databricks and than use Jobs API as described here:https://docs.databricks.com/dev-tools/api/latest/jobs.htmlfollowing endpoints are available:POST https://<databricks-instance>/api/2.1/jobs/crea...
I want to know weather an arrow key or the escape character has ben pressed. But in order to check which arrow key has been pressed I need to do multiple blocking getch-calls bc the arrow-key sequence is bigger than 1 char. This is a problem when I c...
I am setting up an external metastore to connect my Databricks cluster. Which is the preferred and recommended Hive metastore version? Also are there any preference or recommendations on the database instance size/type
@Harikrishnan Kunhumveettil we use databricks runtime 7.3LTS and 9.1LTS. And external hive metastore hosted on azue sql db. Using global init script I have set spark.sql.hive.metastore.version 2.3.7 and downloaded spark.sql.hive.metastore.jars f...
I am trying to read a 16mb excel file and I was getting a gc overhead limit exceeded error to resolve that i tried to increase my executor memory with,spark.conf.set("spark.executor.memory", "8g")but i got the following stack :Using Spark's default l...
I want to be able to refresh tokens generated on behalf of a service principal via Token Management API, just like with any other service where OAuth is used and refresh token endpoint is available. Allowing indefinite or very long expiration for acc...
Refresh option would be useful.In Azure you could use Azure automation to make "refresh" script: delete if still existscreate token via: "databricks tokens create" put it to Azure Key Vault with expiration data
How we can persist 300 million records? What is the best option to persist data databricks hive metastore/Azure storage/Delta table?What is the limitations we have for deltatables of databricks in terms of data?We have usecase where testers should be...
You can certainly store 300 million records without any problem.The best option kinda depends on the use case. If you want to do a lot of online querying on the table, I suggest using delta lake, which is optimeized (using z-order, bloom filter, par...
Truncate False not working in Delta table. df_delta.show(df_delta.count(),False)Computer size Single Node - Standard_F4S - 8GB Memory, 4 coresHow much max data we can persist in Delta table in Parquet file and How fast we can retrieve data.
Hello,I have created my table in Databricks, at this point everything is perfect i got the same value than in my CSV. for my column "Exposure" I have :0 0,00
1 0,00
2 0,00
3 0,00
4 0,00
...But when I load my fi...
Hi @Anis Ben Salem ,How do you read your CSV file? do you use Pandas or Pyspark APIs? also, how do you created your table?could you share more details on the code you are trying to run?
@Alina Bella - If werners' answer solved the issue, would you be happy to mark their answer as best? That will help others find the solution more easily in the future.
Regarding writing (sink) is possible without problem via foreachBatch .I use it in production - stream autoload csvs from data lake and writing foreachBatch to SQL (inside foreachBatch function you have temporary dataframe with records and just use w...