The repos API has a patch method to update a repo in the workspace (to do a git pull).We would please like to verify: is this method fully synchronous? Is it guaranteed to only return a 200 after the update is complete? Or, would immediately referenc...
Hello,I have a question about DNS addresses Databricks uses.In our network configuration, we are using custom VNet injection with no public IPs, and are required to use on-premises corporate DNS.Therefore we would like to add necessary entries to on-...
Hi @Wlodek Bielski , Please refer to the doc :- https://docs.microsoft.com/en-us/azure/databricks/administration-guide/cloud-configurations/azure/on-prem-network
Hi - Could you please help me on how can I create a scala notebook to perform the below tasksEncrypt a text file using the gpgUpload the file to amazon s3 storageverify the file exists in amazon s3decrypt the encrypted file to verify no issuesApprec...
Hi @sriwin p , There is encrypt/decrypt file test case code from PR to the https://github.com/sbt/sbt-pgp repository. It provides an example of usage of PGP file encryption/decryption with :package com.jsuereth.pgp
import org.specs2.mutable._
im...
I have created custom UDF's that generate logs. These logs can be flushed by calling another API exposed which is exposed by an internal layer. However I want to call this API just after the execution of the UDF comes to an end. Is there any way of d...
@Krishna Kashiv May be ExecutorPlugin.java can help. It has all the methods you might required. Let me know if it works or not.You need to implement this interface org.apache.spark.api.plugin.SparkPluginand expose it as spark.plugins = com.abc.Imp...
How to properly configure the jar containing the class and spark plugin in Databricks?During DBR 7.3 cluster creation, I tried by setting the spark.plugins, spark.driver.extraClassPath and spark.executor.extraClassPath Spark configs by copying the ja...
Hello @Krishna Kashiv - I don't know if we've met yet. My name is Piper and I'm a community moderator here. Thank you for your new question. It looks thorough! Let's give it a while to see what our members have to say. Otherwise, we will circle back...
I saw a similar question in a discussion 5 years ago and back then this option was not available. https://community.databricks.com/s/question/0D53f00001HKHhNCAX/markup-in-databricks-notebookI wonder if this feature has been added. It is possible to d...
My email address is the owner of an account in a particular standard plan tenancy. I would like to transfer ownership to another user so they can change billing details, and take admin access going forward. How can this be accomplished?
Hi @David Allen To transfer account owner rights, contact your Databricks account representative. This is applicable for both legacy and E2 accounts.https://docs.databricks.com/administration-guide/account-settings/account-console.html#access-the-ac...
You may have noticed that the local SQL endpoint is not listed in the options for getting started with APEX. The local SQL endpoint is an extremely useful feature for getting ADO.NET web services started. I say check this uk-dissertation.com review f...
Hi GuysIs there any documentation on where the /databricks-datasets/ mount is actually served from?We are looking at locking down where our workspace can reach out to via the internet and as it currently stands we are unable to reach this.I did look ...
Hello Mat, Thanks for letting us know. Would you be happy to mark your answer as best if that will solve the problem for others? That way, members will be able to find the solution more easily.
Thanks to everyone who joined the Best Practices for Your Data Architecture session on Getting Workloads to Production using CI/CD. You can access the on-demand session recording here, and the code in the Databricks Labs CI/CD Templates Repo. Posted ...
when trying to rundatabricks configure --host https://adb-xxxxxx.10.azuredatabricks.net/ -f {dbutils.secrets.get("scopre", "secret")}Error message :-RuntimeError: Unable to read the token from "[REDACTED]"
Using Databricks spark submit job, setting new cluster1] "spark_version": "8.2.x-scala2.12" => OK, works fine2] "spark_version": "9.1.x-scala2.12" => FAIL, with errorsException in thread "main" java.lang.ExceptionInInitializerError
at com.databricks...
this has been resolved by adding the following spark_conf (not thru --conf) "spark.hadoop.fs.file.impl": "org.apache.hadoop.fs.LocalFileSystem"example:------"new_cluster": { "spark_version": "9.1.x-scala2.12", ... "spark_conf": { "spar...
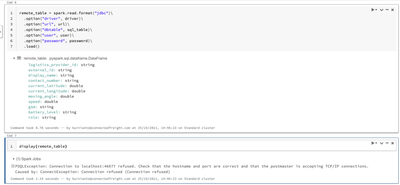
Hi everyone,I am using SSH tunnelling with SSHTunnelForwarder to reach a target AWS RDS PostgreSQL database. The connection got through, however when I tried to display the retrieved data frame it always throws "connection refused" error. Please see ...
hi @Kurnianto Trilaksono Sutjipto ,This seems like a connectivity issue with the url you are trying to connect to. It fails during the display() command because read is a lazy transformation and it will not be executed right away. On the other hand,...
Dear community, we are using the Azure Databricks service and wondering if uploading a file to the DBFS (or to a storage accessed directly from a notebook in Databricks) could be a potential security threat. Imagine you upload some files with 'malici...
Hi, I'm running couple of Notebooks in my pipeline and I would like to set fixed value of 'spark.sql.shuffle.partitions' - same value for every notebook. Should I do that by adding spark.conf.set.. code in each Notebook (Runtime SQL configurations ar...
Hi, Thank you all for the tips. I tried before to set this option in Spark Config but didn't work for some reason. Today I tried again and it's working :).