Hi, i try to create a table using UI, but i keep getting the error "error creating table <table name> create a cluster first" even when i have a cluster alread running. what is the problem?
Hello guys, I'm trying to read JSON files from the s3 bucket. but no matter what I try I get Query returned no result or if I don't specify the schema I get unable to infer a schema.I tried to mount the s3 bucket, still not works.here is some code th...
Please refer to the doc that helps you to read JSON. If you are getting this error the problem should be with the JSON schema. Please validate it.As a test, create a simple JSON file (you can get it on the internet), upload it to your S3 bucket, and ...
I am able to load data for single container by hard coding, but not able to load from multiple containers. I used for loop, but data frame is loading only last container's last folder record only.Here one more issue is I have to flatten data, when I ...
for sure function (def) should be declared outside loop, move it after importing libraries,logic is a bit complicated you need to debug it using display(Flatten_df2) (or .show()) and validating json after each iteration (using break or sleep etc.)
Hi as it is transaction tables (there are history commits and snapshot). I would not store there images or videos as it can be saved few times and you will have high storage costs, it can also be slow when data is big.I would definitely store images,...
Is there any reason this command works well:%sql
SELECT * FROM datanase.table WHERE salary > 1000returning 2 rows, while the below:%sql
delete FROM datanase.table WHERE salary > 1000ErrorError in SQL statement: AssertionError: assertion failed:...
DELETE FROM (and similarly UPDAT. aren't supported on the Parquet files - right now on Databricks, it's supported for Delta format. You can convert your parquet files into delta using CONVERT TO DELTA, and then this command will work for you.
Running Azure Databricks Enterprise DBR 8.3 ML running on a single node, with Python notebook. I have 2 small Spark dataframes that I am able source via credential passthrough reading from ADLSgen2 via `abfss://` method and display the full content ...
Modern Spark operates by a design choice to separate storage and compute. So saving a csv to the river's local disk doesn't make sense for a few reasons:the worker nodes don't have access to the driver's disk. They would need to send the data over to...
Hi everyone,
I just learning how to personalize the databricks notebooks and would like to show a logo in a cell.
I installed the databricks cli and was able to upload the image file to the dbfs:
I try to display it like this:
displayHTML("<im...
@Paul Hernandez @Sean Owen @Navneet Tuteja I solved this after I also ran into the same issue where my notebook suddenly wouldn't show an image sitting on the driver in an accessible folder - no matter what I was trying in the notebook the display...
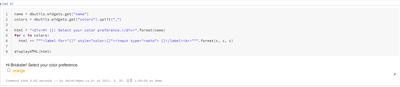
The widget is not shown when I use dbutils while it works perfect with sql.For example, %sql
CREATE WIDGET TEXT state DEFAULT "CA"This one shows me widget.dbutils.widgets.text("name", "Brickster", "Name")
dbutils.widgets.multiselect("colors", "oran...
You can remove that folder so it will be recreated automatically.Additionally every new job run should have new (or just empty) checkpoint location.You can add in your code before running streaming:dbutils.fs.rm(checkpoint_path, True)Additionally you...
I am using a Py function to read some data from a GET endpoint and write them as a CSV file to a Azure BLOB location.My GET endpoint takes 2 query parameters,param1 and param2. So initially, I have a dataframe paramDf that has two columns param1 and ...
Error: missing application resourceGetting this error while running job with spark submit. I have given following parameters while creating job:--conf spark.yarn.appMasterEnv.PYSAPRK_PYTHON=databricks/path/python3--py-files dbfs/path/to/.egg job_m...
Hi,We tried a simulate the question on our end and what we did was packaged a module inside a whl file.Now to access the wheel file we created another python file test_whl_locally.py. Inside test_whl_locally.py to access the content of the wheel file...
Hi @afshin riahi , Yes, Definitely I can help you with it.Please wait while I or someone from the community gets back with a response.Thank you for your patience .
I am using spark structured streaming to read a protobuf encoded message from the event hub. We use a lot of Delta tables, but there isn't a simple way to integrate this. We are currently using K-SQL to transform into avro on the fly and then use Dat...
Hi team, I'm getting weird error in one of my jobs when connecting to Snowflake. All my other jobs (I've got plenty) work fine. The current one also works fine when I have only one coding step (except installing needed libraries in my very first step...