Hello everyone!I was wondering if there is any way to get the subdirectories in which the file resides while loading while loading using Autoloader with DLT. For example:def customer(): return ( spark.readStream.format('cloudfiles') .option('clou...
Hi @Parsa Bahraminejad We haven't heard from you since the last response from @Vigneshraja Palaniraj , and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be...
When using the COPY INTO statement is it possible to reference the current file name in the select staement? A generic example is shown below, hoping I can log the file name in the target table.COPY INTO my_table FROM (SELECT key, index, textData, ...
Hey,we have an issue in that we can access the SQL files whenever the notebook is in the repo path but whenever the CICD pipeline imports the repo notebooks and SQL files to the shared workspace, we can list the SQL files but can not read them.we cha...
@Nermin Yehia yes, as you are moving files to different location manually , just update as can manage permissions in target and that should take care of everything
Hello everyone ! I am trying to pass a Typesafe config file to the spark submit task and print the details in the config file. Code: import org.slf4j.{Logger, LoggerFactory}
import com.typesafe.config.{Config, ConfigFactory}
import org.apache.spa...
I've experenced similar issues; please help to answer how to get this working;I've tried using below to be either /dbfs/mnt/blah path or dbfs:/mnt/blah pathin either spark_submit_task or spark_jar_task (via cluster spark_conf for java optinos); no su...
When I use SQL code like "create table myTable (column1 string, column2 string) using csv options('delimiter' = ',', 'header' = 'true') location 'pathToCsv'" to create a table from a single CSV file stored in a folder within an Azure Data Lake contai...
Hi @andrew li, When you specify a path with LOCATION keyword, Spark will consider that to be an EXTERNAL table. So when you dropped the table, you underlying data if any will not be cleared. So in you case, as this is an external table, you folder s...
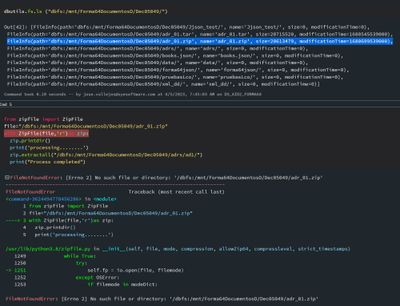
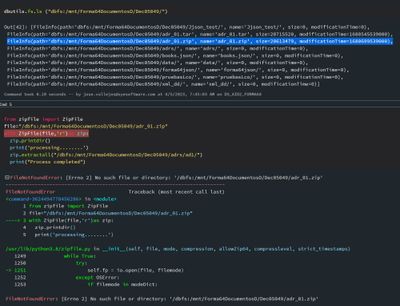
Hello, how are you? I have a small problem. I need to unzip some .zip, tar files. and gz inside these may have multiple files trying to unzip the .zip files i got this errorFileNotFoundError: [Errno 2] No such file or directory: but the files are in ...
Hi @Alfredo Vallejos Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feed...
how to guarantee the index is always following the file's original order no matter what. Currently, I'm using val df = spark.read.options(Map("header"-> "true", "inferSchema" -> "true")).csv("filePath").withColumn("index", monotonically_increasing...
monotonically_increasing_id will not as it is to guarantee that every partition has separate ids. What is the whole code? Do you load directory with a lot of CSVs? What "original order" means? Is it csvs ordered by file creation date, by file name? o...
I have two JSON files, one ~3 gb and one ~5 gb. I am unable to upload them to databricks community edition as they exceed the max allowed up-loadable file size (~2 gb). If I zip them I am able to upload them, but I am also having issues figuring out ...
Hi @Sage Olson Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we...
I have the following error code in databricks when I want to unzip filesFileNotFoundError: [Errno 2] No such file or directory: but the file is there I already tried several ways and nothing worksI have tried modifying by placing/dbfs/mnt/dbfs/mnt/d...
Hello,Concerning Autoloader (based on https://docs.databricks.com/ingestion/auto-loader/schema.html), so far what I understand is when it detects a schema update, the stream fails and I have to rerun it to make it works, it's ok.But once I rerun it, ...
Hi @Lucien Arrio Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thank...
Hi Team, I have a parquet file in s3 bucket which is a delta file I am able to read it but I am unable to write it as a csv file.getting the following error when i am trying to write:A transaction log for Databricks Delta was found at `s3://path/a...
Hi @yuvesh kotiala Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
I have a requirement , I am running 2 Notebooks parallelly I want to overwrite the file parallelly .If 2 Notebooks Try to overwrite the file at the same time , will I lose the data because of overwriting the file at the same time .I want to overwr...
Hi @Rajesh Akshith Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
I want read a json from IO variable using PySpark.My code using pandas:io = BytesIO()ftp.retrbinary('RETR '+ file_name, io.write)io.seek(0)# With pandasdf = pd.read_json(io)What I tried using PySpark, but don't work: io = BytesIO() ftp.retrbinary('...
I have configured a File Notification Autoloader that monitors S3 bucket for binary files. I want to integrate autoloader with workflow job so that whenever a file is placed in S3 bucket, the pipeline job notebook tasks can pick-up new file and start...
Hi @Saravanan Ponnaiah Hope everything is going great.Does @odoll odoll response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
How can I delete a file in DBFS with Illegal character?Someone put the file named "planejamento_[4098.]___SHORT_SAIA_JEANS__.xlsx" inside the folder /FileStore and I can delete it, because of this error: java.net.URISyntaxException: Illegal character...
try this %sh ls -li /dbfsif the file is located in a subdirectory you can change the path mentioned above.the %sh magic command gives you access to linux shell commands.