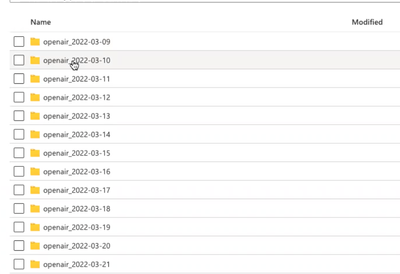
I have a set of .hdf files that I want to distribute and read on Worker nodes under Databricks environment using PySpark. I am able to read .hdf files on worker nodes and get the data from the files. The next requirement is that now each worker node ...
We are distributing pbids files providing the connection info to databricks. It contains options passed to the "Databricks.Catalogs " function implementing the connection to databricks. It is my understanding that databricks has made this together wi...
Hi @Erik Parmann Does @Hubert Dudek response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
I have 150k small csv files (~50Mb) stored in S3 which I want to load into a delta table.All CSV files are stored in the following structure in S3:bucket/folder/name_00000000_00000100.csvbucket/folder/name_00000100_00000200.csvThis is the code I use ...
Hi @Jan R Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
I have a yaml file inside one of the sub dir in Databricks, I have appended the repo path to sys. Still I can't access this file. https://docs.databricks.com/_static/notebooks/files-in-repos.html
We would like to have a robust reader that ensure that the data we read and write using the autoloader respect the schema which is provided to the autoloader reader.We also provide the option "badRecordsPath" (refer to https://docs.databricks.com/spa...
We get new files from a third-p@rty each day. The files could be the same or different. However, each day all csv files arrive in the same dated folder. Is it possible to use autoloader on this structure?We want each csv file to be a table that gets ...
Hi @Stephanie Rivera , Just a friendly follow-up. Do you still need help, or @Hubert Dudek (Customer) 's response help you to find the solution? Please let us know.
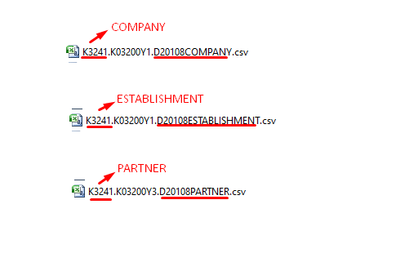
Hello everyone, I have a directory with 40 files.File names are divided into prefixes. I need to rename the prefix k3241 according to the name in the last prefix.I even managed to insert the csv extension at the end of the file. but renaming files ba...
Hi @welder martins How are you doing?Thank you for posting that question. We are glad you could resolve the issue. Would you want to mark an answer as the best solution?Cheers
I am reading a Kafka input using Spark Streaming on databricks and trying to deserialize it. The input is in the form of thrift. I want to create a file of .thrift format to provide schema but am unable to do it. Even if I create the file locally and...
Hi @John Constantine ,Just checking if you still need help or not anymore. If you do, please share as much details and logs as possible, so we would be able to help better.
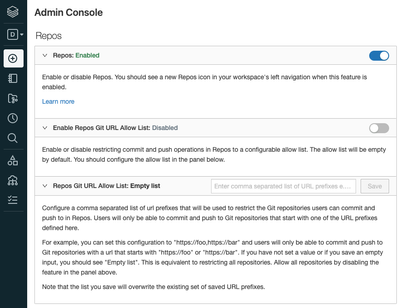
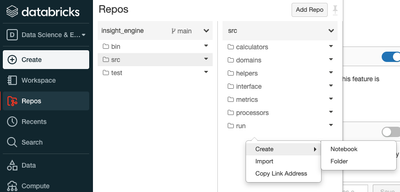
"Arbitrary files in Databricks Repos", allowing not just notebooks to be added to repos, is in Public Preview. I've tried to activate it following the instructions in the above link but the option doesn't appear in Admin Console. Minimum requirements...
Hi @Tom Turner , An admin can enable this feature as follows:Go to the Admin Console.Click the Workspace Settings tab.In the Repos section, click the Files in Repos toggle.After the feature has been enabled, you must restart your cluster and refresh...
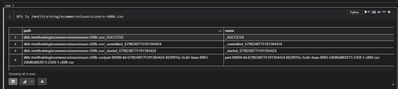
I tried to use %fs head to print the contents of a CSV file used in a training%fs head "/mnt/path/file.csv"but got an error saying cannot head a directory!?Then I did %fs ls on the same CSV file and got a list of 4 files under a directory named as a ...
Hello there,I currently have the problem of deleted files still being in the transaction log when trying to call a delta table. What I found was this statement:%sql
FSCK REPAIR TABLE table_name [DRY RUN]But using it returned following error:Error in ...
I built a machine learning model:lr = LinearRegression()
lr.fit(X_train, y_train)which I can save to the filestore by:filename = "/dbfs/FileStore/lr_model.pkl"
with open(filename, 'wb') as f:
pickle.dump(lr, f)Ideally, I wanted to save the model ...
Hi @Michael Okelola , When you store the file in DBFS (/FileStore/...), it's in your account (data plane). While notebooks, etc. are in the Databricks account (control plane). By design, you can't import non-code objects into a workspace. But Repos ...
What would be the best way of loading several files like in a single table to be consumed?https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2019-10.csvhttps://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2019-11.csvhttps://s3.amazonaws...
Hello,How to show the properties of the folders/files from DBFS ?Currently i am using this command :display(dbutils.fs.ls("dbfs:/"))But it only shows :pathnamesizeHow to show these properties ? : CreatedBy (Name)CreatedOn (Date)ModifiedBy (Name)Modi...