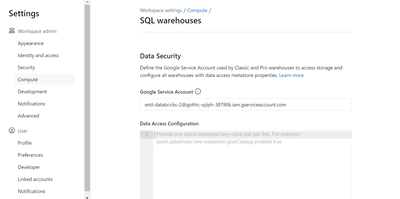
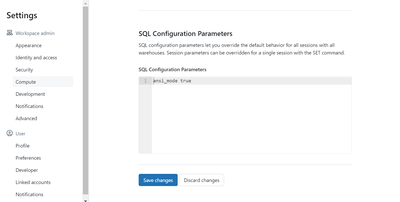
Weirdly, if you ask the Databricks assistant, it tells you it does support recursive CTE and will give you sample code for it. If you follow up and press it on details it doubles down and says it supports it, but tell you the runtime version informat...
Hi @JoshGallant, We're thrilled to hear that you found the Delta Live Tables Best Practices session fantastic!
Your enthusiasm and engagement at DAIS 2023 were truly appreciated. We wanted to let you know that the Databricks Community team will be ba...
Hi @EricIto, We're thrilled to hear that you had such a positive experience at DAIS 2023, especially with the Data Engineering track! Your feedback is greatly appreciated, and we're glad that you found the training valuable.
We're excited to announce...
Having a great time at the summit and learning about the advances with AI. The advantages of adding the ability to use english as a new programming language and the advantage that it will bring to the companies that adapt to the future of Databricks....
Hi @Peston, We're thrilled to hear that you had a great experience at the summit and found the sessions on AI advancements and the use of English as a new programming language insightful. It's exciting to see the potential benefits these advancements...
I have a storage account dexflex and two containers source and destination. Source container has directory and files as below: results
search
03
Module19111.json
Module19126.json
04
Module1129...
I can list out the file using dbutils but can not able to read files in databricks. PFB in screenshot. I can able to see the file using dbutils.fs.ls but when i try to read this file using read_excel then it is showing me an error like "FileNotFound...
Hello there,I am trying to start a serverless databricks SQL cluster in GCP. I am following this databricks doc: https://docs.gcp.databricks.com/en/admin/sql/serverless.htmlI have checked that all my requirements are fulfilled for activating the clus...
Hi @Keyurishah_, We're thrilled to hear that you had a great experience at DAIS 2023! Your feedback is valuable to us, and we appreciate you taking the time to share it on the community platform.
We wanted to let you know that the Databricks Communit...
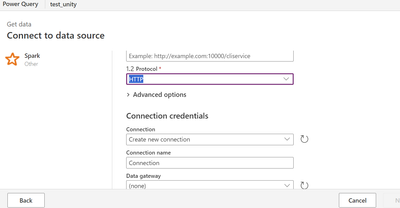
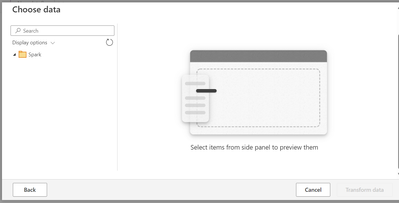
Hi All,Currently I trying to connect databricks Unity Catalog from Powerapps Dataflow by using spark connector specifying http url and using databricks personal access token as specified in below screenshot: I am able to connect but the issue is when...
thanks for replying @Kaniz . I am using my user person token to connect and I have all access on catalog,schema and tables. I am able to view in Databricks Sql editor but not via Spark connector in power apps. It still shows me Is there anything else...
When I am running a query on Databricks itself from notebook, it is running fine and giving me results. But the same query when executed from FastAPI (Python, using databricks library) is giving me "TypeError: 'NoneType' object is not iterable".I can...
Hi @Nastia, The “TypeError: ‘NoneType’ object is not iterable” error typically occurs when you try to iterate over a variable that has a value of None.
Let’s explore some possible solutions to address this issue:
Check for None before Iterating: ...
How/how many databricks notebooks should be created to populate multiple silver delta tables, all having different and complex transformations ? What's the best practice -1. create a notebook each for a silver table ?2. push SQL transformation logic ...
Hi @jitesh, When organizing your Databricks Notebooks for multiple silver Delta tables with different and complex transformations, it’s essential to follow best practices.
Here are some recommendations:
Separate Notebooks for Each Layer:
Bronze L...
Hi Team,We are currently planning to implement Databricks cell-level code parallel execution through the Python threading library. We are interested in comprehending the resource consumption and allocation process from the cluster. Are there any pot...
Hi @Phani1, Implementing Databricks cell-level code parallel execution through the Python threading library can be beneficial for performance, but there are some considerations to keep in mind.
Let’s break it down:
Resource Consumption and Alloca...
In azure AD, it's shows users are synced to Databricks. But in Databricks, it's showing users is not a part of the group. The user is not part of only one group , he is part of remaining groups. All the syncing works fine till yesterday. I don't now ...
Hi @Fresher, It sounds like you’re experiencing an issue with user synchronization between Azure AD and Databricks.
Let’s troubleshoot this together!
Here are some steps you can take to resolve the issue:
Check SCIM Provisioning Configuration:
En...
In my SQL data transformation pipeline, I'm doing chained/cascading window aggregations: for example, I want to do average over the last 5 minutes, then compute average over the past day on top of the 5 minute average, so that my aggregations are mor...
Hi @chloeh, You’re working with a Spark SQL data transformation pipeline involving chained window aggregations.
Let’s look at your code snippet and see if we can identify the issue.
First, let’s break down the steps you’ve implemented:
You’re read...
Hi Databricks community,Hope you are doing well.I am trying to create an external table using a Gzipped CSV file uploaded to an S3 bucket.The S3 URI of the resource doesn't have any file extensions, but the content of the file is a Gzipped comma sepa...
Hi @AdityaM, It seems you’re encountering an issue with creating an external table from a Gzipped CSV file in Databricks using an S3 URI without file extensions.
Let’s address this step by step.
SerDe (Serializer/Deserializer):
When creating an e...