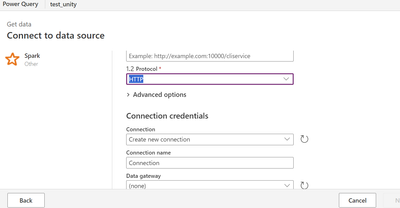
Hi All,Currently I trying to connect databricks Unity Catalog from Powerapps Dataflow by using spark connector specifying http url and using databricks personal access token as specified in below screenshot: I am able to connect but the issue is when...
thanks for replying @Kaniz . I am using my user person token to connect and I have all access on catalog,schema and tables. I am able to view in Databricks Sql editor but not via Spark connector in power apps. It still shows me Is there anything else...
When I am running a query on Databricks itself from notebook, it is running fine and giving me results. But the same query when executed from FastAPI (Python, using databricks library) is giving me "TypeError: 'NoneType' object is not iterable".I can...
Hi @Nastia, The “TypeError: ‘NoneType’ object is not iterable” error typically occurs when you try to iterate over a variable that has a value of None.
Let’s explore some possible solutions to address this issue:
Check for None before Iterating: ...
How/how many databricks notebooks should be created to populate multiple silver delta tables, all having different and complex transformations ? What's the best practice -1. create a notebook each for a silver table ?2. push SQL transformation logic ...
Hi @jitesh, When organizing your Databricks Notebooks for multiple silver Delta tables with different and complex transformations, it’s essential to follow best practices.
Here are some recommendations:
Separate Notebooks for Each Layer:
Bronze L...
Hi Team,We are currently planning to implement Databricks cell-level code parallel execution through the Python threading library. We are interested in comprehending the resource consumption and allocation process from the cluster. Are there any pot...
Hi @Phani1, Implementing Databricks cell-level code parallel execution through the Python threading library can be beneficial for performance, but there are some considerations to keep in mind.
Let’s break it down:
Resource Consumption and Alloca...
In azure AD, it's shows users are synced to Databricks. But in Databricks, it's showing users is not a part of the group. The user is not part of only one group , he is part of remaining groups. All the syncing works fine till yesterday. I don't now ...
Hi @Fresher, It sounds like you’re experiencing an issue with user synchronization between Azure AD and Databricks.
Let’s troubleshoot this together!
Here are some steps you can take to resolve the issue:
Check SCIM Provisioning Configuration:
En...
In my SQL data transformation pipeline, I'm doing chained/cascading window aggregations: for example, I want to do average over the last 5 minutes, then compute average over the past day on top of the 5 minute average, so that my aggregations are mor...
Hi @chloeh, You’re working with a Spark SQL data transformation pipeline involving chained window aggregations.
Let’s look at your code snippet and see if we can identify the issue.
First, let’s break down the steps you’ve implemented:
You’re read...
Hi Databricks community,Hope you are doing well.I am trying to create an external table using a Gzipped CSV file uploaded to an S3 bucket.The S3 URI of the resource doesn't have any file extensions, but the content of the file is a Gzipped comma sepa...
Hi @AdityaM, It seems you’re encountering an issue with creating an external table from a Gzipped CSV file in Databricks using an S3 URI without file extensions.
Let’s address this step by step.
SerDe (Serializer/Deserializer):
When creating an e...
Hello everyone,I work as a Business Intelligence practitioner, employing tools like Alteryx or various low-code solutions to construct ETL processes and develop data pipelines for my Dashboards and reports. Currently, I'm delving into Azure Databrick...
Hi @kazinahian, In the Azure ecosystem, you have a few options for building ETL (Extract, Transform, Load) data pipelines, including low-code solutions.
Let’s explore some relevant tools:
Azure Data Factory:
Purpose: Azure Data Factory is a clou...
I can list out the file using dbutils but can not able to read files in databricks. PFB in screenshot. I can able to see the file using dbutils.fs.ls but when i try to read this file using read_excel then it is showing me an error like "FileNotFound...
Hi @MohammadWasi, It seems like you’re encountering a common issue related to file paths when working with pd.read_excel in Python.
Let’s troubleshoot this step by step:
Check the File Path:
First, ensure that the Excel file (abcd.xls) is indeed ...
Hello there,I am trying to start a serverless databricks SQL cluster in GCP. I am following this databricks doc: https://docs.gcp.databricks.com/en/admin/sql/serverless.htmlI have checked that all my requirements are fulfilled for activating the clus...
Hi @ashraf1395, It seems you’re encountering some confusion while trying to enable the serverless SQL cluster in Databricks on Google Cloud Platform (GCP).
Let’s troubleshoot this together!
First, I appreciate that you’ve followed the steps outlin...
Hi,I have configured 20 different workflows in Databricks. All of them configured with job cluster with different name. All 20 workfldows scheduled to run at same time. But even configuring different job cluster in all of them they run sequentially w...
Honestly you shouldn't have any kind of limitation executing diferent workflows.I did a test case in my Databricks and if you have your workflows with a job cluster your shouldn't have limitation. But I did all my test in Azure and just for you to kn...
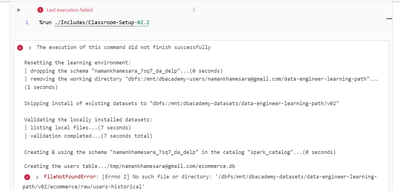
Hi Databricks Community,I am following https://customer-academy.databricks.com/learn/course/1266/data-engineering-with-databricks?generated_by=575333&hash=6edddab97f2f528922e2d38d8e4440cda4e5302a this course provided by databricks. In this when I am ...
Hi @namankhamesara, Thank you for reaching out! It appears there might be an issue with accessing the data for your course. To expedite your request and resolve this issue promptly, please list your concerns on our ticketing portal. Our support staff...
As per info available ingestion time clustering makes use of time of the time a file is written or ingested in databricks. In a use case where there is new delta table and an etl which runs in timely fashion(say daily) inserting records, am able to ...
Hi @Shazam, Great questions! Let’s break down each scenario:
Initial Data Migration: When migrating data from an existing platform to Databricks, you might have a large initial load of records. In this case, ingestion time clustering can still be...
Hi,I have a DLT pipeline that applies changes from a source table (cdctest_cdc_enriched) to a target table (cdctest), by the following code:dlt.apply_changes( target = "cdctest", source = "cdctest_cdc_enriched", keys = ["ID"], sequence_by...
Hi @Anske, It seems you’re encountering an issue with your Delta Live Tables (DLT) pipeline where updates from the source table are not being correctly applied to the target table.
Let’s troubleshoot this together!
Pipeline Update Process: Whe...
I am using a tqdm progress bar to monitor the amount of data records I have collected via API. I am temporarily writing them to a file in the DBFS, then uploading to a Spark DataFrame. Each time I write to a file, I get a message like 'Wrote 8873925 ...
Hi @halox6000, To stop the progress bar output from tqdm, you can use the disable argument. Set it to True to silence any tqdm output. In fact, it will not only hide the display but also skip the progress bar calculations entirely1. Here’s an examp...