Hi, I tried to deploy a Feature Store packaged model into Delta Live Table using mlflow.pyfunc.spark_udf in Azure Databricks. This model is built by Databricks autoML with joined Feature Table inside it.And I'm trying to make prediction using the fol...
i am trying to extract some data into databricks but tripping all over openpyxl, newish user of databricks..from openpyxl import load_workbookdirectory_id="hidden"scope="hidden"client_id="hidden"service_credential_key="hidden"container_name="hidden"s...
Hi @Vanessa Van Gelder Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question. Thanks.
Hi,This happened across 4x seemingly unrelated workflows at the same time of the day - all 4x workflows eventually completed successfully. It appeared that all workflows sat idling despite triggering via the Jobs API. The two symptoms I have observed...
We have a source table that receives daily append operations, but the rows created within the last 30 days in this table can be updated or deleted. Thus, the source table is not exactly a streaming source.Our processing workflow involves performing "...
Hi @Pongsakorn Chairatanakul Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please...
I implemented Databrick on AWS and the template is used i3.xlarge. Could I use it for down Instance Family for cost optimization? Is i3.xlarge the minimum size to use Databricks in a trial mood? Thanks
Thank you so much for your reply to my question, @Vidula Khanna @Kaniz Fatma . After I took some study time, I understood the basics, and then I am on the way to Databricks.
Hi,Do you know any good resources about Databricks performance improvements(like improving query performances, monitoring/resolving performance bottlenecks etc)?Thanks
Hi @Ömer Özsakarya We haven't heard from you since the last response from @Lakshay Goel , and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be helpful to ...
Code to create a data frame:from pyspark.sql import SparkSessionspark=SparkSession.builder.appName("oracle_queries").master("local[4]")\ .config("spark.sql.warehouse.dir", "C:\\softwares\\git\\pyspark\\hive").getOrCreate()from pyspark.sql.functions ...
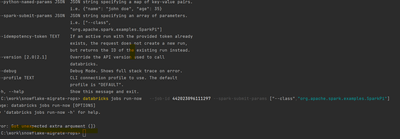
Could anyone tell me what could be wrong with my command to submit a spark job with params( If I don’t have --spark-submit-params, it’s fine). Please see the attached snapshot.
I’m trying to use sql query on azure-databricks with distinct sort and aliasesSELECT DISTINCT album.ArtistId AS my_alias
FROM album ORDER BY album.ArtistIdThe problem is that if I add an alias then I can not use not aliased name in the order by cla...
When using Azure Data Factory to coordinate the launch of Databricks jobs - can you specify which cluster policy to apply to the job, either explicitly or implicitly?
you could, but not from ADF's UI. You need to edit the json of the linked service, adding a 'policyId' parameter in the 'typeProperties' object, pointing to the cluster policy ID from Databricks (which you could find in Databricks' URL).
Hi, I'm trying to process a small dataset (less than 300 Mb) composed by five queries that run with spark. The end result of those queries is parsed using python and merged into a data frame. Then I try to write this to a delta lake table using featu...
Hello, we have recently found that it's my user in particular that casues the memory issue. Two other users in my organization can run the same notebook without problems, but my user consistenly consumes all available ram and crashes the cluster... a...
After creating the delta pipeline, I would like to get details from the dlt maintenance job automatically created by Databricks, like the scheduled time when the dlt maintenance tasks will be executed. However, it seems the Job API 2.1 doesn't cover ...
Hi @Debayan Mukherjee ,Actually the Databricks Jobs API documentation has not been fixed yet. The parameter `job_type` should be included in the list endpoint request documentation. Please do this in order to avoid unnecessary questions here in the ...
Hi, I'm running all my jobs on one big cluster, I'm just concerned is there a solution on how we could clear cache resulted by a notebook in the end of the job when its done? hence it does not causing any memory problem sometime from one to another, ...
Hi @krisna math We haven't heard from you since the last response from @Debayan Mukherjee , and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be helpful to...
Hi @sreeranjani thevan Great to meet you, and thanks for your question!Let's see if your peers in the community have an answer to your question. Thanks.