I have integrated gitlab with my azure databricks repo, I am able to push and pull commits from the databricks UI, I want to checkout to a specific commit version via databricks UI.Note: I am aware that via the gitlab i have checkout to specific vers...
After getting more context on databricks repo in details,Currently databricks doesn't support checkout of repo to specific commit.databricks provides only limited functionality mentioned belowAdd a repo and connect remotely laterClone a repo connecte...
Hi, I have several streaming jobs, however one of them uses the Trigger.AvailableNow. The issue is that it gets stuck when there is no events or finishes ingesting all events. The expected behavior would be the job being shutdown.I've already checked...
Normally, our ELT framework takes in batches one by one and loads the data into target tables. But if more than one batches come in at the same time, the framework will break due to the concurrency issue that multiple sources are trying to write the ...
Attention Community! For a limited period, we are offering a generous 50% discount on training at the Data + AI Summit. Simply apply the code FLS4vop5ep during the registration process. Hurry, though, as this offer will expire on June 12, 2023. Don'...
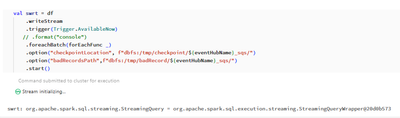
HiBelow i am trying to read data from kafka, determine whether its fraud or not and then i need to write it back to mongodbbelow is my code read_kafka.pyfrom pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types i...
Hi Saswata,Can you remove the filter and see if it is printing output to console?kafka_df5=kafka_df4.filter(kafka_df4.status=="FRAUD")Thanks and RegardsSwetha Nandajan
Hi everyoneI am exploring automl, and I met a strange problem - after I launch a classification experiment on my personal newly created cluster (screenshot attached) it successfully performs data exploration, but after that, all runs fail after appro...
Hi Qwetroman,we can see the following error message in the notebook - ExecutionTimeoutError: Execution timed out before any trials could be successfully run. Please increase the timeout for AutoML to run some trials.What's the size of the dataset? St...
Greetings, When trying to run the following command: %sh
mlflow sagemaker build-and-push-containerI get the following error:/databricks/python3/lib/python3.9/site-packages/click/core.py:2309: UserWarning: Virtualenv support is still experimental and ...
Within the UI it is possible to "Select tables for refresh" for a specific Delta Live Tables Workflow. I often use it to make a full refresh on smaller tables during development. Unfortunately, when an error occurs during the full refresh on selected...
Hi, I want to change the default time zone for SQL Warehoue in the SQL Persona. When I try to Edit the SQL warehouse settings in the "SQL Warehouses" section, I am not able to find any setting where I can set the time zone. I am aware that I can set ...
Thanks. I am aware of the SET TIME ZONE command but I need to run this command every time I start the SQL warehouse. I am looking for a way to change the default time zone of the SQL warehouse. Something like "spark.sql.session.timeZone GMT+10" that ...
Hi, This looks like a browser issue. Could you please try it with some other browser? Or clear the cookies and caches of the same browser and confirm? Please tag @Debayan with your next comment so that I will get notified. Thank you!
Hello,I have some nested columns with hyphen i.e. sample-1 in struct column, recently DLT pipeline has started throwing synatx error. Before May 24, 2023, this was working fine.Is this a new bug in May 2023 release?After clearing table and table's da...
Hi @Rishabh Tomar We haven't heard from you since the last response from @Kaniz Fatma . Kindly share the information with us, and in return, we will provide you with the necessary solution. Thanks and Regards
Timestamp columns which are extracted from source databases using jdbc read are getting converted to different timezone and is not matching with source timestamp. Could anyone suggest how can we get same timestamp data like source data?
Hi @Dinu Sukumara We haven't heard from you since the last response from @Werner Stinckens . Kindly share the information with us, and in return, we will provide you with the necessary solution.Thanks and Regards
Dear Community,I want to understand from you all - How do you debug your codes when using Databricks?Have you tried the Variable Explorer of Databricks? This allows the users to view at-a-glance all the variables defined in their notebooks, inspect...
I just create code in notebooks that allow me to check outputs at different steps. These methods usually include print statements or .display() of dataframes. If youre working with lots of data the .show(truncate=100,vertical=True) may help you. I ha...
@Gerard Blackburns :Calculating the cost or billing for Azure SQL Server instances involves considering the Azure SQL Database Unit (DBU) pricing model. DBUs are the unit of measure for the consumption of Azure SQL Database resources. To calculate t...
I am trying to setup delta live tables pipelines to ingest data to bronze and silver tables. Bronze and Silver are separate schema. This will be triggered by a daily job. It appears to run fine when set as continuous, but fails when triggered.Table...
Hi @Jennette Shepard Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answ...