We should have network setup from databricks Vnet to the on-prem SQL server. Then the connection from the databricks notebook using JDBC using Windows authenticated username/password - https://docs.microsoft.com/en-us/azure/databricks/data/data-sourc...
We use SQL Server to store data. I would like to connect to SQL to pull manipulate and sometimes push data back. I've seen some examples online of connecting but I cannot successfully re-create.
You can use jTDS library from maven, add this to your cluster. Once installed, you can write the below code to connect to your Database.Code in Scala will be:import java.util.Properties
val driverClass = "net.sourceforge.jtds.jdbc.Driver"
val serve...
Hi, this post have a practice exams:https://files.training.databricks.com/assessments/practice-exams/PracticeExam-DCADAS3-Python.pdf?_gl=1*1kqf0to*_gcl_aw*R0NMLjE2ODI0NDkyOTcuRUFJYUlRb2JDaE1JNWFTZ2d0ekZfZ0lWSkc1dkJCMVQ2UTJNRUFBWUFpQUFFZ0pOc3ZEX0J3RQ.
Hi, I am running concurrent notebooks in concurrent workflow jobs in job compute cluster c5a.8xlarge with 5-7 worker nodes. Each job has 100 concurrent child notebooks and there are 10 job instances. 8/10 jobs gives the error the spark driver has sto...
Hi @uzair mustafa Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so...
Hi, I have set up a webhook which will send the event to a lambda in AWS. I validate the event through the credentials given while creating the webhook but sometimes the event that is being sent from databricks does not contain authorization in the h...
@Muthu Kumaran :If the event being sent from Databricks to your Lambda function sometimes does not contain authorization headers, you may need to modify your webhook configuration or Lambda function code to handle this situation. Here are a few sugg...
I am in a situation where I have a notebook that runs in a pipeline that creates a "live streaming table". So, I cannot use a language other than sql in the pipeline. I would like to format a certain column in the pipeline using a scala code (it's a ...
I successfully passed the test after completing the course but I haven't received any certification or badge yet.Any Help is much appreciated. @Vidula Khanna
Hi @Sushma Rani,Thank you for reaching out! Please submit a ticket to our Training Team here: https://help.databricks.com/s/contact-us?ReqType=training and our team will get back to you shortly.
My data is a dump of JSON response from an API. The schema of the json iscol_name data_type
data array<struct<attributes:struct<name: String, age: Int relationships:struct<address:struct<data:arraay<struct<id: long, type: string>>>>>>>
...
Hi @Ashwin Bhaskar, You can use the SQL JOIN operation to join the data and include arrays based on the id field. Here's an example SQL query that should accomplish this:SELECT
data.attributes.name AS name,
data.attributes.age AS age,
included...
Hi all, I have a Azure Databricks Setup (non-premium) and an ADLS Gen 2.0 setup. I am trying to access the ADLS Gen 2.0 containers via a simple access key mode for testing.There is no error, if the ADLS Gen 2.0 is set to "Enable from all networks". B...
Hi, can you check two link belowhttps://learn.microsoft.com/en-us/azure/databricks/getting-started/connect-to-azure-storagehttps://docs.databricks.com/storage/azure-storage.html
Hi All,I have 20 tables in source sql DB and we need to create pipeline to incrementally load data into target database .Can some one please suggest me best approach to achieve this using Azure Databricks please?Should i use merge Into ? Copy Into? o...
Hi @SUDHANSHU RAJ,Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers...
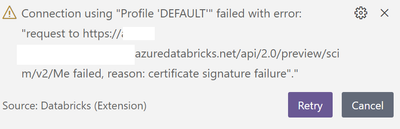
Hi everyone,I'm trying to use the new Databricks extension (v0.3.10) for VS code (v1.77.3).I face this problem when connecting to our workspace:This problem persists when I tried to login through az CLI with our SSO, or through local config using PAT...
@Minh Duc Nguyen :It seems like the error you are facing is due to a failure in verifying the SSL certificate of your Databricks workspace. To resolve this, you need to add the custom CA certificate to your VS Code settings. Here's how you can do it...
I do have multiple groups created in my databricks account and I have databricks cli installed on my mac. Some of the cli functions return errors that i cannot find solution for. databricks groups listReturns:Error: b'{"error_code":"INTERNAL_ERROR","...
@kenan hasanov which version python you have installed on your machine please, you need to have 3-3.6 or 2-2.7.9 above , please try to go with latest one as you are only seeing issues with few functions. please raise issue in case if you are still f...
guys, i cannot recover my password at my databricks workspace. I tried to reset my password by using the reset my password buttons in both login and admin console, but i am not getting the reset email. I already checked my spam box and i'm getting em...
We are implementing a lakehouse architecture and using Notebook to transform data from object storage. Most of the time our source is database for which there one folder per table in object storage.We have structure like below for various notebooksGO...