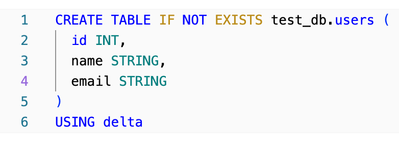
Hi,I have encountered a problem using spark, when creating a dataframe from a raw json source.I have defined an schema for my data and the problem is that when there is a mismatch between one of the column values and its defined schema, spark not onl...
@Farzad Bonabi :Thank you for reporting this issue. It seems to be a known bug in Spark when dealing with malformed decimal values. When a decimal value in the input JSON data is not parseable by Spark, it sets not only that column to null but also ...
I have set up Databricks cluster to work with AWS Glue Catalog by enabling the spark.databricks.hive.metastore.glueCatalog.enabled to true. However, when I create a Delta table on Glue Catalog, the schema reflected in the AWS Glue Catalog is incorrec...
Hi, could you please refer to something or explain in more detail your point about querying Delta Lake files directly instead of through the AWS Glue catalog and why it was highlighted as a best practice?
I would like to create a schedule in Databricks that runs a job on the first working day of every month (working days referring to Monday through Friday). I tried using Cron syntax but didn't have any luck. Is there any way we can schedule this in Da...
@NDK_1 - Cron syntax won't allow the combination of day of month and day of week. you can try creating two different schedules - one for the first day, second day of the month and then add custom logic to check if it is an working day and then trigg...
I have written a CTE in Spark SQL WITH temp_data AS (
......
)
CREATE VIEW AS temp_view FROM SELECT * FROM temp_view; I get a cryptic error. Is there a way to create a temp view from CTE using Spark SQL in databricks?
In the CTE you can't do a CREATE. It expects an expression in the form of expression_name [ ( column_name [ , ... ] ) ] [ AS ] ( query )where expression_name specifies a name for the common table expression.If you want to create a view from a CTE, y...
Does anyone know if there's a way to specify an alternate Unity schema in a DLT workflow using the @Dlt.table syntax? In my case, I’m looping through folders in Azure datalake storage to ingest data. I’d like those folders to get created in different...
if i update the value in xml then autoloader not detecting the changes.same for delete/remove column or property in xml. So request to you please help me to fix this issue
It seems that the issue you're experiencing with Autoloader not detecting changes in XML files might be related to how Autoloader handles schema inference and evolution.
Autoloader can automatically detect the schema of loaded XML data, allowing you...
HiI'm trying to deploy the databricks jobs from dev to prod environment. I have jobs in dev environment and using azure devops, I deployed the jobs in the code format to prod environment. Now when I use the post method to create the job programmatica...
Hi,Is there a quick and easy way to copy files between different environments? I have copied a large number of files on my dev environment (unity catalog) and want to copy them over to production environment. Instead of doing it from scratch, can I j...
If you want to copy files in Azure, ADF is usually the fastest option (for example TB of csvs, parquets). If you want to copy tables, just use CLONE. If it is files with code just use Repos and branches.
Hi @MarinD, Delta Live Tables (DLT) pipelines can indeed use Unity Catalog as a destination.
Here’s how you can specify the catalog and target schema:
Create a DLT Pipeline with Unity Catalog:
When creating a DLT pipeline, in the UI, select “Uni...
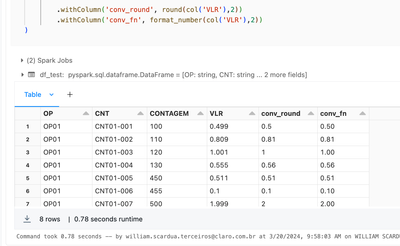
Hi @William_Scardua, In Databricks, you can format decimal values without rounding them using a couple of approaches. Let’s explore some options:
Using substring: You can use the substring function to extract a specific number of decimal places f...
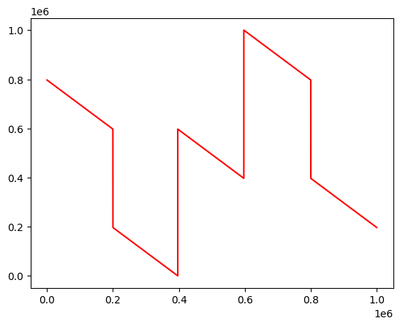
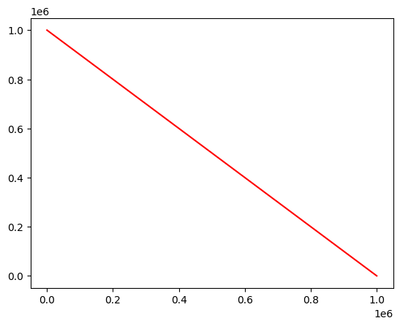
I came across a pyspark issue when sorting the dataframe by a column. It seems like pyspark only orders the data within partitions when having multiple worker, even though it shouldn't. from pyspark.sql import functions as F
import matplotlib.pyplot...
@Kaniz Sorry if I have to ask again, but I am a bit confused by this.I thought, that pysparks `orderBy()` and `sort()` do a shuffle operation before the sorting for exact this reason. There is another command `sortWithinPartitions()` that does not do...
Currently my Databricks Metastore is in the the same location as the data for my production catalog. We are moving the data to a separate storage account. In advance of this, I'm curious if there is a way to determine the size of the metastore itself...
Hi @ac0, Let’s explore how you can determine the size of your Databricks Metastore and estimate the storage requirements for the Azure Storage Account hosting the metastore.
Metastore Size:
The metastore in Unity Catalog is the top-level contain...
I am unable to display the below stream after reading it.df= spark.readStream.format("cloudFiles")\.option("cloudFiles.format", "csv")\.option("header", "true")\.option("delimiter", "\t")\.option("inferSchema", "true")\.option("cloudFiles.connectionS...
Hi @Dikshant,
Unfortunately, stateful streaming queries do not support schema evolution. This means that once a query starts with a particular schema, you cannot change it during query restarts.To resolve this issue, you can set the cloudFiles.schem...
Aim-Installation of external libraries(wheel file) in Data bricks through synapse using new job clusterSolution- I have followed the below steps:I have created a pipeline in synapse that consists of a notebook activity that is using a new job cluster...
Hi @IshaBudhiraja,
Confirm that the library version matches the one you intended to install.Ensure that the library is installed in the same Python environment where your notebook or script is running.