databricks learning self paced course Databricks Certified Associate Developer for Apache Spark 3 has below issues 1) Full screen button is disabled, difficult to see small font and stress on eyes.PFA2) courses do not have captions. Sometimes it is d...
Hi @Smitha Nelapati Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us ...
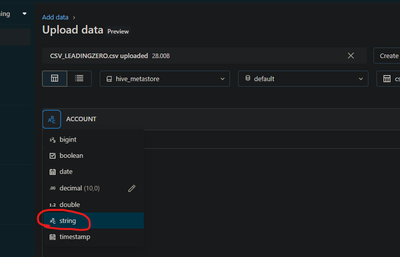
use add data UI, add csv manually, even set data type as string, the leading zero will be missingexample csvval1,val20012345, abcafter load data, 123,abc is stored in table
Hello,I'm working with an on-premise R session and would like to connect to Databricks using sparklyr. RStudio server in this case is not an option.I would like to use jdbc. I tested RJDBC + DBI and can conect locally and perform operations. However,...
Hi,I am trying to run my code from a scala fatjar on azure-databricks, which connects to snowflake for the data.I usually run my jar on 9.1 LTS.However when I run on 10.4 LTS the performace was 4x degraded and in the log it says WARN SnowflakeConnect...
I also encountered the similar problem. This is a snippet from my log file:22/12/18 09:36:28 WARN SnowflakeConnectorUtils$: Query pushdown is not supported because you are using Spark 3.2.0 with a connector designed to support Spark 3.1. Either use t...
I would like to register for a new 14-day free trial account as my existing one expires. I received the welcome email to validate my email address. I followed the link to set my password and it redirected me to the Databricks console page, but the pa...
You can just log in to portal.azure.com and create a new databricks workspace, and there is an option 14 days premium free trial. I use that approach every time.
I had appeared for Databricks Lakehouse Fundamentals Accreditation for both V1 and V2. Recently I came to know that when you take V1 test, and you get a badge and certificate - once you take V2 test, it updates that same badge and certificate to the ...
I just run `cursor.columns()` via the python client and I'll get back a `org.apache.hive.service.cli.HiveSQLException` as response. There is also a long stack trace, I'll just paste the last bit because it might be illuminating: org.apache.spark.sql....
Hello, I'm pretty new to Databricks in general and Delta Live Tables specifically. My problem statement is that I'd like loop through a set of files and run a notebook that loads the data into some Delta Live Tables. Additionally, I'd like to include...
I have recently passed my Databricks Certified Machine Learning Associate exam on Tuesday (04/01) and still have not received my badge on accredible website.Please advise.
@Timothy Hartanto First of all congratulations on your achievement, you will be receiving your certificate and the badge to the registered mail address in 24-48 hours post-completion of your examination. Hope this helps!!All the very best for your f...
Im reading avro file and loading into table. The avro data is nested data.Now from this table im trying to extract the necessary elements using spark sql. Using explode function when there is array data. Now the challenge is there are cases like the ...
Hi @manoj kumar An easiest way would be to make use of unmanaged delta tables and while loading data into the path of that table, you can enable mergeSchema to be true. This handles all the schema differences, incase column is not present as null an...
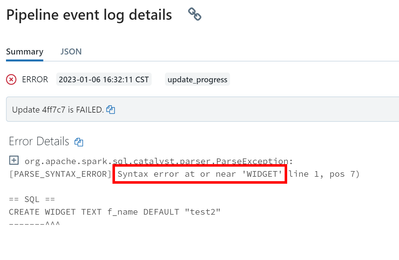
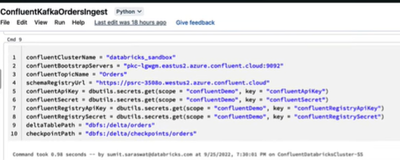
Hello I am a newbie in this field and trying to access confluent kafka stream in Databricks Azure based on a beginner's video by Databricks. I have a free trial of Databricks cluster right now. When I run the below notebook, it errors out on line 5 o...
For testing, create without secret scope. It will be unsafe, but you can post secrets as strings in the notebook for testing. Here is the code which I used for loading data from confluent:inputDF = (spark
.readStream
.format("kafka")
.option("kafka.b...
All,I have a column, RateAdj that is defined as DECIMAL(15,5) and I can see that the value is 4.00000, but when this gets inserted into my table it shows as just 4.%sql
SELECT LTRIM(RTRIM(IFNULL(FORMAT_NUMBER(RateADJ, '0.00000'), '0.00000')))This i...
The value goes to 10,000 values and having the things done to run a fast execution, and I am also Sociology Dissertation Help with the reduction of pages.
I am trying to upgrade our Databricks workspace from standard to premium but running into issues. The workspace is currently deployed in a managed VNET.I tried the migration tool as well as just re-creating a premium workspace with the same parameter...
Hi, I have same situation when trying to upgrade from Standard to Premium on Azure.My error: "ConflictWithNetworkIntentPolicy","message":"Found conflicts with NetworkIntentPolicy. Details: Subnet or Virtual Network cannot have resources or properties...
Lineage - It would be nice if the lineage in Unity would allow for API calls that could add additional lineage information, somehow. I am not certain exactly what would be nice. But some sort of feature to include source systems in it.
Pureview is quite popular to be integrated to solve this issue. I think lineage in the unity catalog is designed to be auto-generated. I know there are information tables, but I never manually manipulated them.
I am having to use Databricks SQL dashboard for some analysis, it seems very clunky. If i have multiple queries, is it possible to apply the same filters to all the queries in the dashboard or do i have to duplicate the filters for each query in the ...
Same issue here. According the docs, using query filters with the same name and values should result in a single dashboard filter. However, filters are duplicated. I also tried using this setting but no success