- 824 Views
- 3 replies
- 2 kudos
Resolved! Disable auto-complete (tab button)
Hello. How could we disable autocomplete that appears with tab button? Thank you
- 824 Views
- 3 replies
- 2 kudos
Hello. How could we disable autocomplete that appears with tab button? Thank you
HI all,I have a table in MongoDB Atlas that I am trying to read continuously to memory and then will write that file out eventually. However, when I look at the in-memory table it doesn't have the correct schema.Code here:from pyspark.sql.types impo...
Hi @sharonbjehome , This has to be checked thoroughly via a support ticket, did you follow: https://docs.databricks.com/external-data/mongodb.html Also, could you please check with mongodb support, Was this working before?
I would like to know how many count of each categories in each year, When I run count, it doesn't work.
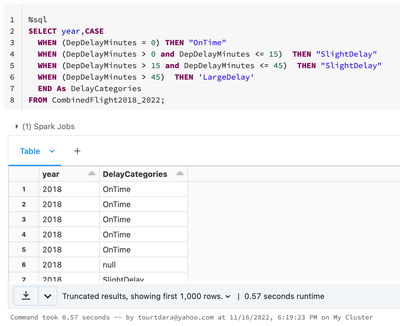
Hi, @Dara Tourt , When you say it does not work, what is the error? You can run count aggregate function. https://docs.databricks.com/sql/language-manual/functions/count.htmlPlease let us know if this helps.
I can read all csvs under an S3 uri byu doing:files = dbutils.fs.ls('s3://example-path')df = spark.read.options(header='true', encoding='iso-8859-1', dateFormat='yyyyMMdd', ignoreLeadingWhiteSpace='true', i...
Hi @Anthony Wang As of now, I think that's the only way. Please refer: https://docs.databricks.com/external-data/csv.html#pitfalls-of-reading-a-subset-of-columns. Please let us know if this helps.
I am running my PySpark data pipeline code on a standard databricks cluster. I need to save all Python/PySpark standard output and standard error messages into a file in an Azure BLOB account.When I run my Python code locally I can see all messages i...
This is the approach I am currently taking. It is documented here: https://stackoverflow.com/questions/62774448/how-to-capture-cells-output-in-databricks-notebook from IPython.utils.capture import CapturedIO capture = CapturedIO(sys.stdout, sys.st...
I have just passed Fundamentals Accreditation i dont have the badge
Hi @FRANCISCO LORA @Kaniz Fatma knows more than me but you could probably submit a ticket to Databricks' Training Team here: https://help.databricks.com/s/contact-us?ReqType=training who will get back to you shortly.
We Are Among The Most Reliable Used Laptop Sellers In Calicut. A Wide Variety Of Laptops From Different Brands To Suit Different Budgets Are Available At Us. The used laptops are in good condition and cost a fraction of what a brand-new laptop would....

I used DBR version 11.0
Thank you, I did all steps from Ales's suggestion but still not successfully
import org.apache.spark.sql._import scala.collection.JavaConverters._import com.microsoft.azure.eventhubs._import java.util.concurrent._import scala.collection.immutable._import org.apache.spark.eventhubs._import scala.concurrent.Futureimport scala.c...
The dataframe to write needs to have the following schema:Column | Type ---------------------------------------------- body (required) | string or binary partitionId (*optional) | string partitionKey...
I'm running on 11.3 LTS. Expected Behavior:Databricks Notebook Behavior (it does nothing): You can also do `shell.set_next_input("test", replace=True)` to replace the current cell content which also doesn't work on Databricks. `set_next_input` stores...
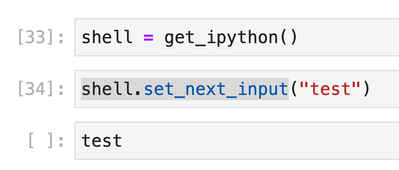
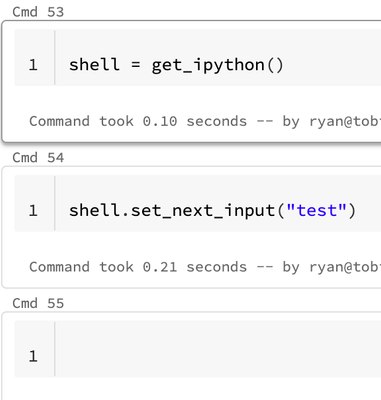
Hi @Ryan Eakman, Can you try the DBR version 11.2?
In the documentation https://registry.terraform.io/providers/databricks/databricks/latest/docs https://docs.gcp.databricks.com/dev-tools/terraform/index.html I could not find documentation on how to provision Databricks workspaces in GCP. Only cre...
Hi @horatiu guja Does @Debayan Mukherjee response answer your question?If yes, would you be happy to mark it as best so that other members can find the solution more quickly? Else, we can help you with more details.
Hi , im trying to setup DLT pipeline ,its a basic pipeline for testing purpose im facing the issue while starting the pipeline , any help is appreciated Code :@dlt.table(name="dlt_bronze_cisco_hardware")def dlt_cisco_networking_bronze_hardware(): ret...
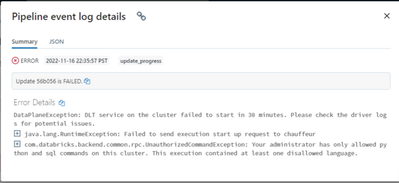
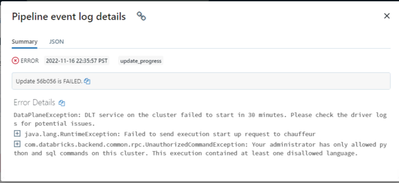
Hi @Arumugam Ramachandran seems like you have a spark config set on your DLT job cluster that allows only python and SQL code. Check the spark config (cluster policy).In any case, the python code should work. Verify the notebook's default language, ...
The date field is getting changed while reading data from source .xls file to the dataframe. In the source xl file all columns are strings but i am not sure why date column alone behaves differentlyIn Source file date is 1/24/2022.In dataframe it is ...
Hi Team, @Merca Ovnerud I am also facing same issue , below is the code snippet which I am using df=spark.read.format("com.crealytics.spark.excel").option("header","true").load("/mnt/dataplatform/Tenant_PK/Results.xlsx")I have a couple of date colum...
Given that there are three different kinda of cluster modes, when is it appropriate to use each one?
Standard clustersA Standard cluster is recommended for a single user. Standard clusters can run workloads developed in any language: Python, SQL, R, and Scala.High Concurrency clustersA High Concurrency cluster is a managed cloud resource. The key be...
SELECT *, yrs_to_mat, CASE WHEN < 3 THEN "under3" WHEN => 3 AND < 5 THEN "3to5" WHEN => 5 AND < 10 THEN "5to10" WHEN => 10 AND < 15 THEN "10to15" WHEN => 15 THEN "over15" ELSE null END AS maturity_bucket FROM mat...
Hi @Anne-Marie Wood ,I think it's more SQL general issue:you are not comparing any value to `< 3`it should be something like :WHEN X < 3 THEN "under3" SELECT *, yrs_to_mat, CASE WHEN X < 3 THEN "under3" WHEN X => 3 AND <...
| User | Count |
|---|---|
| 1601 | |
| 736 | |
| 343 | |
| 284 | |
| 247 |