Currently I load multiple parquet file with this code:df = spark.read.parquet("/mnt/dev/bronze/Voucher/*/*")(Inside the Voucher folder, there is one folder by date. Each one containing one parquet file)How can I add a column into this DataFrame, that...
Is there a possibility to downgrade the Delta Table protocol versions minReader from 2 to 1 and maxWriter from 5 to 3? I have set the TBL properties to 2 and 5 and columnmapping mode to rename the columns in the DeltaTable but the other users are rea...
Hi @Yaswanth velkur, We haven’t heard from you since the last response from @Youssef Mrini and me, and I was checking back to see if our suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be hel...
Hi I would like to know if anyone interested to volunteer in person Databricks meetup.Please share your thoughts, and we can talk further about the logistics Thank you
I've been building out a few pipelines in DLT and noticed that the usefulness of the user interface has started breaking down at a glance. I've attached a screenshot of one of my pipelines. It's not very far along and it's already pretty rough. You c...
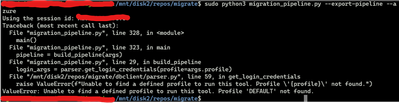
cat ~/.databrickscfg looks like this (with the correct token/host values in place of xxxxxx)[DEFAULT]host = xxxxxxtoken = xxxxxxjobs-api-version = 2.0The command I run to start the pipeline with default configured credentials is :sudo python3 migrati...
I simply do left join on two data frame and both data frame content i was able to print.Here is the code looks like:-df_silver = spark.sql("select ds.PropertyID,\ ds.* from dfsilver as ds LEFT JOIN dfaddmaster as dm \ ...
In the docs it's mention that "if you use Azure Database for MySQL as an external metastore, you must change the value of the lower_case_table_names property from 1 (the default) to 2 in the server-side database configuration."However "lower_case_tab...
I've been observing as we added more workspaces and users to those workspaces that fetching users per workspace is now taking 11 minutes or more.Our automation to provision group access is now unacceptably long. I've noted that the UI doesn't suffer...
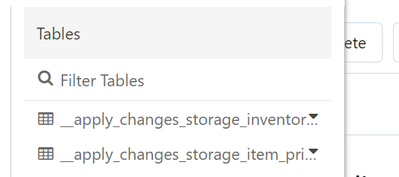
Hi there,I am using apply_changes (aka. Delta Live Tables Change Data Capture) and it works fine. However, it seems to automatically create a secondary table in the database metastore called _apply_storage_changes_{tableName}So for every table I use ...
I am dealing with values ranging from 10^9 to 10^-9 , the sum of values can go up to 10^20 and need accuracy. So I wanted to use Decimal Data type [ Using SQL in Data Science & Engineering workspace]. However, I got to know the peculiar behavior of D...
Hello Everyone,I understand that there is no best answer for this question. So, I could only do the same thing I found when I surfed the net.The method I found works whenIf you know the range of values you deal with (not just the input data but also ...
Using the code below I am attempting to connect to a PlanetScale MySQL database. I get the following error: java.sql.SQLException: error parsing url : Incorrect port value. However the port is the default 3306, and I have used the correct url based o...
I added a grand total row to a "Count" in SQL, which I needed for some counter visualisations. I used the "ROLL UP" command to get the grand total.However, I have a pie chart which references the same count, and so the grand total row has been added...
I am receiving SSL handshake error even though the trust-store I have created is based on server certificate and the fingerprint in the certificate matches the trust-store fingerprint.kafkashaded.org.apache.kafka.common.errors.SslAuthenticationExcept...
Hi @Jayanth Goulla , worth a try ,https://stackoverflow.com/questions/54903381/kafka-failed-authentication-due-to-ssl-handshake-failedDid you follow: https://docs.microsoft.com/en-us/azure/databricks/spark/latest/structured-streaming/kafka?
HI all,I have a table in MongoDB Atlas that I am trying to read continuously to memory and then will write that file out eventually. However, when I look at the in-memory table it doesn't have the correct schema.Code here:from pyspark.sql.types impo...
Hi @sharonbjehome , This has to be checked thoroughly via a support ticket, did you follow: https://docs.databricks.com/external-data/mongodb.html Also, could you please check with mongodb support, Was this working before?