- 2557 Views
- 2 replies
- 3 kudos
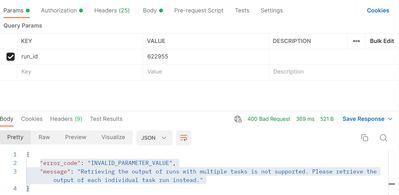
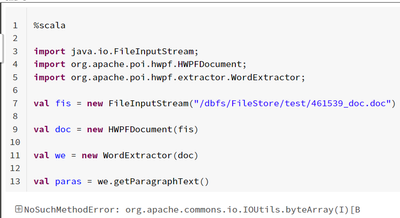
%run not printing notebook output when using 'Run All' command
I have been using the %run command to run auxiliary notebooks from an "orchestration" notebook. I like using %run over dbutils.notebook.run because of the variable inheritance, troubleshooting ease, and the printing of the output from the auxiliary n...
- 2557 Views
- 2 replies
- 3 kudos
Latest Reply
- 3 kudos
Hi @Aaron Petry Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks
- 3 kudos