I have set up a Spark standalone cluster and use Spark Structured Streaming to write data from Kafka to multiple Delta Lake tables - simply stored in the file system. So there are multiple writes per second. After running the pipeline for a while, I ...
Hey there @Kim Abasch Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
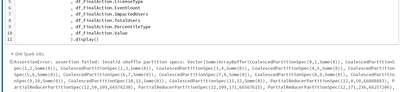
I hv a complex script which consuming more then 100GB data and have some aggregation on it and in the end I am simply try simply write/display data from Data frame. Then i am getting issue (assertion failed: Invalid shuffle partition specs: ).Pls hel...
Hi @John William , We haven't heard from you on the last response from @Hubert Dudek and @Werner Stinckens, and I was checking back to see if their suggestions helped you. Also, Please don't forget to click on the "Select As Best" button whenever ...
I get an error when writing dataframe to s3 location Found invalid character(s) among " ,;{}()\n\t=" in the column names of yourI have gone through all the columns and none of them have any special characters. Any idea how to fix this?
Hi @John Constantine, We haven’t heard from you on the last response from @Emilie Myth , and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others. Other...
How can I re-write this statement in a way that is compatible for Databricks?DECLARE @DATE_BEGIN_TEST AS DATE = DATEADD(DAY, - 60, GETDATE());DECLARE @DATE_END_TEST AS DATE = GETDATE();
Hi @Joseph Collins , We haven’t heard from you on the last response from me, and I was checking back to see if you have a resolution yet. If you have any solution, please do share that same with the community as it can be helpful to others. Otherwis...
I am trying to order the way that widgets are shown in Databricks, but I cannot. For example, I have two text widgets (start date and end date). Databricks shows "end_date" before "start_date" on top, as the default order is alphabetical. Obviously, ...
Hi @Reza Rajabi , We haven’t heard from you on the last response from @Prabakar Ammeappin , and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please do share that with the community as it can be helpfu...
Now that delta live pipeline is GA we are looking to convert our existing processes to leverage it. One thing that remains unclear is how to populate new delta live tables with historical data? Currently we are looking to use CDC by leveraging create...
@Kaniz Fatma Hello, sorry for the delayed response. The guide does not answer how to incorporate existing delta tables that container historical data into a delta live pipeline. We ended up changing the source data to pull from the existing bronze t...
hi @trung nguyen have you tried reducing the cluster size? With the community version, we have limitations. Further please share the cluster config. Normally such errors are generated when we reach/exceed the limit set on the cloud.
The following doesn't work for me:%sql
SELECT user_id, array_size(education) AS edu_cnt
FROM users
ORDER BY edu_cnt DESC
LIMIT 10; I get an error saying: Error in SQL statement: AnalysisException: Undefined function: array_size. This function is nei...
Hey there @Michael Carey Hope everything is going great!We are glad to hear that you were able to find a solution to your question. Would you be happy to mark an answer as best so that other members can find the solution more quickly?Cheers!
I am building a dashboard and at the end of I am using a widget to reset it. At that time I want all the outputs to be removed. Is there a way to do this in python?
You can build your dashboard in SQL experience instead. There is a nice API to manage them https://docs.databricks.com/sql/api/queries-dashboards.htmlRegarding "clear state and cell outputs" when you run notebook as a job state is not saved in the no...
The workspaceID is usually in the URL of the workspace. For example:https://myworkspace.com/?o=12345The workspace id in this case is 12345. You can also just share the URL with your solutions architect.
After accumulating many updates to a delta table,like,keyExample bigint GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1),my identity column values are in the hundreds of millions. Is there any way that I can reset this value through vacuumi...
Hey there @Andrew Fogarty Does @Werner Stinckens's response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly? Else please let us know if you need more help. Thanks!
I following the https://docs.databricks.com/dev-tools/databricks-connect.html#intellij-scala-or-java to obtain spark-avro jar since databricks have it's custom from_avro method to use with kafka schema registry, But i am not able to find spark-avro j...
I am running dbsqlcli in windows 10. I have put together the attached cmd file to pull the identity column data from a series of our tables into individual CSVs so I can upload then to a PostgreSQL DB to do a comparison of each table to those in the ...