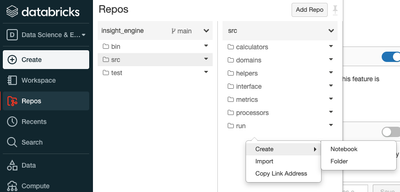
We are currently setting up CI/CD for our Databricks workspace using Databricks Repos following the approach described in the offical docs: https://docs.databricks.com/repos.html#best-practices-for-integrating-databricks-repos-with-cicd-workflowsObvi...
Hirun below code line at spark-shell through db-connectIt throw exception:java.lang.ClassCastException: cannot assign instance of java.lang.invoke.SerializedLambda to field org.apache.spark.rdd.MapPartitionsRDD.f of type scala.Function3 in instance o...
Software 2.0 is one of 10 most important trends which will shape next decade.Idea of Software 2.0 was first time presented in 2017 by Andrej Karpathy. He wrote that Neural networks are not just another classifier, they represent the beginning of a fu...
Hi! I have some jobs that stay idle for some time when getting data from a S3 mount on DBFS, this are all SQL queries on Delta, how can I know where is the bottle neck, duration, cue? to diagnose the slow spark performance that I think is on the proc...
We found out we were regeneratig the symlink manifest for all the partitions on this case. And for some reason it was executed twice, at start and end of the job.delta_table.generate('symlink_format_manifest')We configured the table with:ALTER TABLE ...
Hi folks,I have an issue. It's not critical but's annoying.We have implemented a Spark Structured Streaming Application.This application will be triggered wire Azure Data Factory (every 8 minutes). Ok, this setup sounds a little bit weird and it's no...
@Markus Freischlad Looks like the spark driver was stuck. It will be good to capture the thread dump of the Spark driver to understand what operation is stuck
Hello,I'm writing this because I have tried a lot of different directions to get a simple model inference working with no success.Here is the outline of the job# 1 - Load the base data (~1 billion lines of ~6 columns)
interaction = build_initial_df()...
It is hard to analyze without Spark UI and more detailed information, but anyway few tips:look for data skews some partitions can be very big some small because of incorrect partitioning. You can use Spark UI to do that but also debug your code a bit...
Hi everybody,Trigger.AvailableNow is released within the databricks 10.1 runtime and we would like to use this new feature with autoloader.We write all our data pipeline in scala and our projects import spark as a provided dependency. If we try to sw...
Hi, I have seen it written in the documentation that standard cluster is recommended for a single user. But why ? What is meant by that ? Me and one of my colleagues were testing it on the same notebook. Both of us can use the same standard all purpo...
High concurrency cluster just split resource between users more evenly. So when 4 people run notebooks in the same time on cluster with 4 cpu you can imagine that every will get 1 cpu. In standard cluster 1 person could utilize all worker cpus as you...
What I am doing:spark_df = spark.createDataFrame(dfnew)spark_df.write.saveAsTable("default.test_table", index=False, header=True)This automatically detects the datatypes and is working right now. BUT, what if the datatype cannot be detected or detect...
just create table earlier and set column types (CREATE TABLE ... LOCATION ( path path)in dataframe you need to have corresponding data types which you can make using cast syntax, just your syntax is incorrect, here is example of correct syntax:from p...
I'm getting attached error in accessing delta lake tables in the data bricks workspaceSummary of error: Could not connect to md1n4trqmokgnhr.csnrqwqko4ho.ap-southeast-1.rds.amazonaws.com:3306 : Connection resetAttached detailed error
Hi,I've been encountering the following error when I try to start a cluster, but the status page says everything is fine. Is something happening or are there other steps I can try?Time2022-03-13 14:40:51 EDTMessageCluster terminated.Reason:Unexpected...
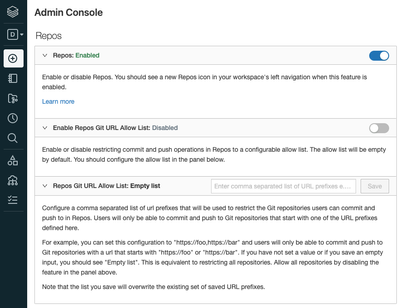
"Arbitrary files in Databricks Repos", allowing not just notebooks to be added to repos, is in Public Preview. I've tried to activate it following the instructions in the above link but the option doesn't appear in Admin Console. Minimum requirements...
Hi @Tom Turner , An admin can enable this feature as follows:Go to the Admin Console.Click the Workspace Settings tab.In the Repos section, click the Files in Repos toggle.After the feature has been enabled, you must restart your cluster and refresh...
Can an mlflow registered model automatically infer the online feature store table, if that model is trained and logged via a databricks feature store table and the table is pushed to an online feature store (like AWS RDS)?
Hi @Saurabh Verma , Feature Store <> SageMaker integration is not fully rolled out yet. We are looking to roll that out in Private Preview mode soon. It will need DynamoDB online store type which will be available soon.