Hello Team,I am quite new to Databricks and I am learning PySpark and Databricks. I am trying to mount a DL Gen2 in Databricks, as part of that I had created app registration, added DL into app registration permissions, created a secret and also adde...
My job started failing with the below error when inserting rows into a delta table. ailing with the below error when inserting rows (timestamp) to a delta table, it was working well before.java.lang.ArithmeticException: Casting XXXXXXXXXXX to int cau...
This is because the Integer type represents 4-byte signed integer numbers. The range of numbers is from -2147483648 to 2147483647.Kindly use double as the data type to insert the "2147483648" value in the delta table.In the below example, The second ...
I have a Java program like this to test out the Databricks JDBC connection with the Databricks JDBC driver. Connection connection = null;
try {
Class.forName(driver);
connection = DriverManager.getConnection(url...
Hi @Jose Gonzalez ,This similar issue in snowflake in JDBC is a good reference, I was able to get this to work in Java OpenJDK 17 by having this JVM option specified:--add-opens=java.base/java.nio=ALL-UNNAMEDAlthough I came across another issue with...
I have configured a Delta Lake Sink connector which reads from an AVRO topic and writes to the Delta lake . I have followed the docs and my config looks like below . { "name": "dev_test_delta_connector", "config": { "topics": "dl_test_avro", "inp...
@Hubert Dudek , Should I be configuring anything with respect to schema in the connector config ? Because I did successfully stage some data from another topic of a different format(JSON_SR) into delta lake table , but its with AVRO topic that I ge...
I am trying to use Databricks Delta Lake Sink Connector(confluent cloud ) and write to S3 . the connector starts up with the following error . Any help on this could be appreciated org.apache.kafka.connect.errors.ConnectException: java.sql.SQLExcepti...
I have a delta table with about 300 billion rows. Now I am performing some operations on a column using UDF and creating another columnMy code is something like thisdef my_udf(data):
return pass
udf_func = udf(my_udf, StringType())
data...
That udf code will run on driver so better not use it for such a big dataset. What you need is vectorized pandas udf https://docs.databricks.com/spark/latest/spark-sql/udf-python-pandas.html
CommunityI'm running a sparklyr "group_by" function and the function returns the following info:# group by event_typeacled_grp_tbl <- acled_tbl %>% group_by("event_type") %>% summary(count = n()) Length Cl...
I should have deleted the post. While your are correct "event_type" should be without quotes the problem was the Summary function. I was using the wrong function it should have been "summarize."
To do that you need to have enabled audit logs (if event already happened and it was not "on" I am afraid now it is too late).For Azure https://docs.microsoft.com/en-us/azure/databricks/administration-guide/account-settings/azure-diagnostic-logsFor A...
I'm running some machine learning experiments in databricks. For random forest algorithm when i restart the cluster, each time the training output is changes even though random state is set. Anyone has any clue about this issue?Note : I tried the sam...
We all have been in the situation at some time where we wonder how to stop liking someone. There could be any reason behind this situation and might be any person: your crush, love, friend, relatives, colleague, or any celebrity. Liking is the strong...
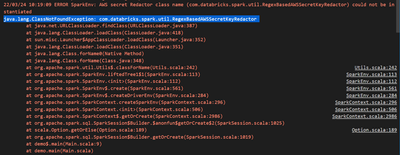
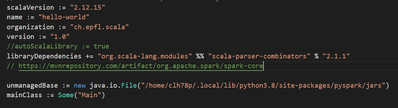
Currently I am learning how to use databricks-connect to develop Scala code using IDE (VS Code) locally. The set-up of the databricks-connect as described here https://docs.microsoft.com/en-us/azure/databricks/dev-tools/databricks-connect was succues...
Hi, I’m trying to read file from S3 root bucket. I can ls all the files but I can’t read it because of access denied. When I mount the same S3 root bucket under some other mountPoint, I can touch and read all the files. I also see that this new mount...
Hi @Atanu Sarkar , @Piper Wilson ,thanks for the replies. Well I don't understand the fact about ownership. I believe that rootbucket is still under my ownership (I created it and I could upload/delete any files through browser without any problem...
Machine learning is sanctionative computers to tackle tasks that have, until now, completely been administered by folks.From driving cars to translating speech, machine learning is driving accolade explosion among the capabilities of computing – serv...
We are currently setting up CI/CD for our Databricks workspace using Databricks Repos following the approach described in the offical docs: https://docs.databricks.com/repos.html#best-practices-for-integrating-databricks-repos-with-cicd-workflowsObvi...