Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Hello,I am trying to assume an IAM role in spark streaming with "s3-sqs" format. It is giving a 403 error. The code is provided below:spark.readStream .format("s3-sqs") .option("fileFormat", "json") .option("roleArn", roleArn) .option("compressi...
Hi!We had an issue on 09/19/2023 - we launched job, run was started, but after 10mins it was cancelled with no reasons. The spark ui is not available (which probably means that claster has not been started at all) and I don’t see any logs even.Could ...
Was it a one time only error or a recurring one?For the former, I'd check if your vCPU quota was not exceeded, or perhaps there was a temporary issue with the cloud provider,... Could be a lot of things (lots of moving parts under the hood).For the ...
Since last Friday i cannot access databricks community any more, which is kinda annoying since my Bachelors dissertation is due in a couple of weeks. I always get the message: "Invalid email address or password Note: Emails/usernames are case-sensiti...
Hi Team,My community edition databricks cred are locked. I am doing very important project. Please help me resolve the issue Please try that it not gets locked in future as well.Email used for login @Retired_mod @Sujitha I have sent a email to commu...
Hi AllLooking to get some help. We are on Unity Catalog in Azure. We have a requirement to use Python to write out PNG files (several) via Matplotlib and then drop those into an ADLS2 Bucket. With Unity Catalog, we can easily use dbutils.fs.cp or fs....
Hmm I read something different - someone else had this error because they used a shared cluster - apparently it does not happen on a single user cluster. All those settings are already done and I am a fully admin.
I've searched in the databricks provider and online and couldn't find out if it is possible to set the `Verbose Audit Logs` to `enabled` using Terraform. Can anybody clarify if it is possible?
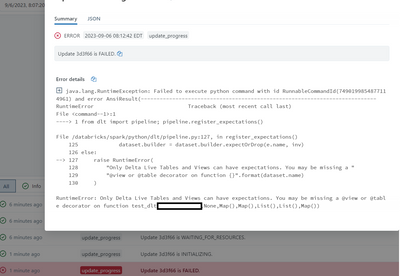
I'm trying to create a task where the source is a Python script located in remote GitLab repo. I'm following the instructions HERE and this is how I have the task set up:However, no matter what path I specify all I get is the error below:Cannot read ...
Hi ,I have a Databricks job that results in a dashboard post run , I'm able to download the dashboard as HTML from the view job runs page , but I want to automate the process , so I tried using the Databricks API , but it says {"error_code":"INVALID_...
Hi All,I set up a DLT pipeline to create 58 bronze tables and a subsequent DLT live table that joins the 58 bronze tables created in the first step. The pipeline runs successfully most times.My issue is that the pipeline fails once every 3/4 runs say...
@jose_gonzalez @Retired_mod - Missed to update the group on the fix. Reached out to Databricks to understand and it was identified that the threads call that i was making was causing the issue. After i removed it - i don't see it happening.
With no change in code, i've noticed that my DLT initialization fails and then an automatic rerun succeeds. Can someone help me understand this behavior. Thank you.
@jose_gonzalez - Missed to update the group on the fix. Reached out to Databricks to understand and it was identified that the threads call that i was making was causing the issue. After i removed it - i don't see it happening.
I have a scheduled job (running in continuous mode) with the following code``` ( spark .readStream .option("checkpointLocation", databricks_checkpoint_location) .option("readChangeFeed", "true") .option("startingVersion", VERSION + 1)...
Hi @Kit Yam Tse Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers y...
Background:I am attempting to download the google cloud sdk on Databricks. The end goal is to be able to use the sdk to transfer files from a Google Cloud Bucket to Azure Blob Storage using Databricks. (If you have any other ideas for this transfer p...
Thanks you for the response!2 Questions:1. How would you create a cluster with the custom requirements for the google cloud sdk? Is that still possible for a Unity Catalog enabled cluster with Shared Access Mode?2. Is a script action the same as a cl...
Hi Team,I am working on migration from Sql server to databricks environment.I encounter a challenge where Databricks and sql server giving different results for date difference function. Can you please help?--SQL SERVERSELECT DATEDIFF(MONTH , '2007-0...
While I was pretty sure it has to do with T-SQL not following ANSI standards, I could not actually tell you what exactly the difference is. So I asked chatgpt and here we go:The difference between DATEDIFF(month, date1, date2) in T-SQL and ANSI SQL ...
Performance Issues experienced when cluster was upgraded from 10.4 LTS to 11.3 LTS , The notebooks were running fine with the existing cluster. Soon after the upgrade the notebooks started to fail or exhaust memory executors etc . Any suggestions?
Hi all,I started using Azure Spot VMs by switching on the spot option when creating a cluster, however in the Azure billing dashboard, after some months of using spot instances, I only have OnDemand PurchaseType. Does someone guess what could be happ...
staticDataFrame = spark.read.format("csv")\ .option("header", "true").option("inferSchema", "true").load("/FileStore/tables/Consumption_2019/*.csv")
when above, I need an option to skip say first 4 lines on each CSV file, How do I do that?
The option... .option("skipRows", <number of rows to skip>) ...works for me as well. However, I am surprised that the official Spark doc does not list it as a CSV Data Source Option: https://spark.apache.org/docs/latest/sql-data-sources-csv.html#data...