Hi all,I was reading the Repos documentation: https://docs.databricks.com/repos.html#migrate-from-run-commandsIt is explained that, one advantage of Repos is no longer necessary to use %run magic command to make funcions available in one notebook to ...
Thank you all for your help! I tried all that was suggested; but I finally realized it was my fault in first place:I was testing Files in Repos with a runtime < 8.4.I was trying to import a file from a DB Notebook instead of a static .py file.Upgradi...
Hi @xiaojun wang please check the blog and let us know if this helps you.https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
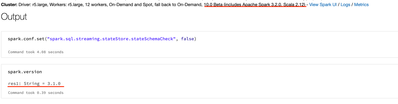
I have databricks runtime for a job set to latest 10.0 Beta (includes Apache Spark 3.2.0, Scala 2.12) .In the notebook when I check for the spark version, I see version 3.1.0 instead of version 3.2.0I need the Spark version 3.2 to process workloads a...
On Databricks, we use the following code to flatten JSON in Python. The data is from a REST API:```df = spark.read.format("json").option("header", "true").option("multiline", "true").load(SourceFileFolder + sourcetable + "*.json")df2 = df.select(psf....
@Dennis D , what's happening here is that more than 2 GB (2147483648 bytes) is being loaded into a single column value. This is a hard-limit for serialization. This KB article addresses it. The solution would be to find some way to have this loaded ...
Feature request: It is possible to add comments to both databricks sql databases and tables. It would be really usefull if these comments could show up (if they are provided) in PowerBI when one connects to the Databricks SQL endpoint, e.g. in this w...
I have a dataframe with the following columns:Key1Key2Y_N_ColCol1Col2For the key tuple (Key1, Key2), I have rows with Y_N_Col = "Y" and Y_N_Col = "N".I need a new dataframe with all rows with Y_N_Col = "Y" (regardless of the key tuple), plus all Y_N_...
I'd use a left-anti join.So create a df with all the Y, then create a df with all the N and do a left_anti join (on key1 and key2) on the df with the Y.then a union of those two.
What is the future of aws?The future of AWS is very promising. So, if you are thinking of a cloud career or want to switch your position to something related to the cloud, I would highly recommend you going for AWS training. No matter what field you ...
Hi @ xiaozy! My name is Kaniz, and I'm the technical moderator here. Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else I will get back to you soon. Thanks.
Basically I'm worried about the scenario where data that gets cached on Databricks SQL endpoints becomes out of sync with the source Delta table. If that were to happen and data was read from the cache it would be out of date/incorrect. Is this a con...
There are 3 types of caching. 1-Databricks SQL UI caching, 2-Query results caching , 3-Delta caching . (1) does not get invalidated. It's like your BI dashboard. BI dashboard needs to be manually refreshed.(2) and (3) gets auto invalidation.pls check...
In Spark SQL, you could use commands like "insert overwrite directory" that indirectly creates a temporary file with the datahttps://docs.databricks.com/spark/latest/spark-sql/language-manual/sql-ref-syntax-dml-insert-overwrite-directory.html#example...
Currently using df.write.format("bigquery") ,Databricks only supports append and Overwrite modes in to writing Bigquery tables.Does Databricks has any option of executing the DMLs like Merge in to Bigquey using Databricks Notebooks.?
@Sumeet Dora , Unfortunately there is no direct "merge into" option for writing to Bigquery using Databricks notebook. You could write to an intermediate delta table using the "merge into" option in delta table. Then read from the delta table and pe...
We need to run VACCUM on one of our biggest tables to free the storage. According to our analysis using VACUUM bigtable DRY RUN this affects 30M+ files that need to be deleted.If we run the final VACUUM, the file-listing takes up to 2h (which is OK) ...
@Gerhard Brueckl we have seen near 80k-120k file deletions in Azure per hour while doing a VACUUM on delta tables, it's just that the vacuum is slower in azure and S3. It might take some time as you said when deleting the files from the delta path. ...
We are using the terraform databricks provier, which is starting a cluster and checking every mount (since there is no mount rest API!). Each mount takes 20 seconds to check, and 99.9% of that time is idle waiting, and it starts a job per mount. If w...
hi @Erik Parmann ,It is possible to do, but you might need to also enable dynamic allocation at the cluster level to be able to make sure your settings are apply at cluster creation . You can find more details here. As best practice, we do not recom...
I am trying to access functions in my coreapi.py by importing in the main notebook, but I have error ModuleNotFoundError: No module named 'coreapi'. I tried by uploading the file into the same folder and I tried creating a python egg and uploading it...