- 562 Views
- 4 replies
- 0 kudos
how to stop dataframe with federated table source to be reevaluated when referenced (cache?)
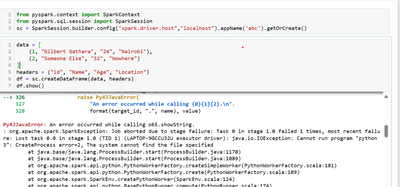
Hi,Would anyone happen to know whether it's possible to cache a dataframe in memory that the result of a query on a federated table?I have a notebook that queries a federated table, does some transformations on the dataframe and then writes this data...
- 562 Views
- 4 replies
- 0 kudos
Latest Reply
- 0 kudos
@daniel_sahal , this is the code snippet:lsn_incr_batch = spark.sql(f"""select start_lsn,tran_begin_time,tran_end_time,tran_id,tran_begin_lsn,cast('{current_run_ts}' as timestamp) as appendedfrom externaldb.cdc.lsn_time_mappingwhere tran_end_time > '...
- 0 kudos