Hi @hal-qna,
Just a friendly follow-up. Have you had a chance to review my colleague's response to your inquiry? Did it prove helpful, or are you still in need of assistance? Your response would be greatly appreciated.
Hi User Community,Requesting some advice on the below issue please:I have 4 Databricks notebooks, 1 That ingests data from a Kafka topic (metric data from many servers) and dumps the data in parquet format into a specified location. My 2nd data brick...
Hi @ndatabricksuser ,
Just a friendly follow-up. Have you had a chance to review my colleague's response to your inquiry? Did it prove helpful, or are you still in need of assistance? Your response would be greatly appreciated.
I'll try to answer this in the simplest possible way
1. Spark is an imperative programming framework. You tell it what it to do, it does it. DLT is declarative - you describe what you want the datasets to be (i.e. the transforms), and it takes care ...
Hi Team,We have a requirement to Encrypt PII data in Silver layer. What is the best way to implement this in DLT? and only users that has security privileges are able to decrypt the PII info.I have done this in the past using Structured Streaming but...
Can you show me how to use the functions built in pyspark using DLT please.Also, trying to implement column/row level security in silver tables that is generated by DLT, but giving me the following error[RequestId=35024c5d-ad05-4f68-a4cb-f3a723f66e1c...
Trying to use displayHTML from w/in a Python module gets a Python exception:NameError: name 'displayHTML' is not definedand I've found no way around this. It seems to be something at the UI layer or something, not a Python function that can be refere...
Holy Guacamole Batman! It works finally!!!! Wow, thanks @ptweir That's awesome! I can go back and update my doc (and code, to just use databricks the same, now, and Jupyter!) and it'll work by default. It's great they fixed it, shame they never told ...
Hello,We have encountered a weird issue in our (old) set-up that looks like a bug in the Unity Catalog. The storage account which we are trying to persist is configured via External Volumes.We have a pipeline that gets XML data and stores it in an RD...
I will post here what worked resolving this error for us, in case someone else in the future encounters this.It turns out that this error appears in this case, when we were using the below command while the directory 'staging2' already exists. To avo...
Let's say I want to check if a condition is false then stop the execution of the rest of the script. I tried with two approaches:1) raising exceptionif not data_input_cols.issubset(data.columns):
raise Exception("Missing column or column's name mis...
In Jupyter notebooks or similar environments, you can stop the execution of a notebook at a specific cell by raising an exception. However, you need to handle the exception properly to ensure the execution stops. The issue you're encountering could b...
Dear Databricks Community Experts,I am working on databricks on AWS with unity catalog.One usecase for me is to uncompress files with many extensions there on S3 Bucket.Below is my strategy:-Move files from S3 to Local file system (where spark driver...
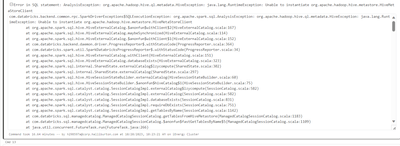
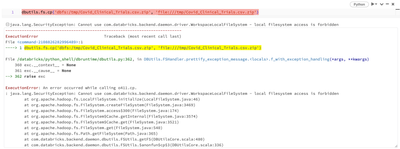
I'm trying to follow along with the blog post Gaining Insights Into Your HL7 Data With Smolder and Databricks-#1 of 3. I was able to finally get a jar file built from the repo using Java 17 and it successfully imports into the cluster. However, when ...
Hi @dfoard ,
It appears that the error is due to attempting to import a Java package in Python code, which isn't supported. The Smolder library is designed to work with Scala code in a Databricks Notebook environment.
To use the com.data...
Hi team,I was giving my exam today and 40 minutes into the exam I was interrupted by the proctor to show the test area. The table had a guitar e string and an almost eaten apple. Nothing else was on the table. Then the proctor asked me to show the ro...
Hi @Akash2 , Thank you for posting your concern on Community!
To expedite your request, please list your concerns on our ticketing portal. Our support staff would be able to act faster on the resolution (our standard resolution time is 24-48 hours).
From a UDF i am trying to return a tuple. But looks like the tuple is not serialising and hence getting empty tuple.Can some help me on this.Attached code and output.
Hi @pankaj_kaushal ,
When you encounter a situation where the tuple returned from a User-Defined Function (UDF) in PySpark isn't serializable, it can cause problems. To make sure the returned object is serializable and can be handled correctly, you ...
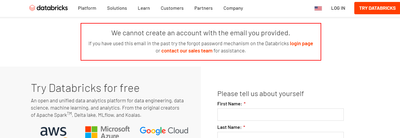
I am trying to sign up for the community edition (https://databricks.com/try-databricks) for use with a databricks academy course. However, I am unable to signup and I receive the following error (image attached). On going to login page (link in ora...
Please look at this link related to the Community - Edition, which might solve your problem.
I appreciate your interest in sharing your Community-Edition query with us. However, at this time, we are not entertaining any Community-Edition questions. W...
We are trying to establish connection between databricks and snowflake through the databricks workspaces running on cluster. Initially we assumed it would be the firewall/network blocking the traffic and tried to add a firewall rule but even after ...
Hi @gopeshr ,
To connect Azure Databricks with Snowflake, you need to ensure the necessary network configurations and firewall rules are in place. Here's a brief guide:
Whitelist Databricks Public IP Addresses:
Obtain the list of Azure Databricks' ...
On this feature IP access lists IP access lists - Azure Databricks | Microsoft Docs, what we observe is that if your IP is not on the access list, you cannot modify the list via API since you are not on trusted location. What if I specify only 1 IP s...
Hey @Chun Sing Chan Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...