Hi All,I want to add a member to a group in databricks account level using rest api (https://docs.databricks.com/api/azure/account/accountgroups/patch) as mentioned in this link I could able to authenticate but not able to add member while using belo...
Hi @pragarwal,
The body you’ve shared is almost correct. However, there’s a small issue. Instead of directly providing the email address as the value, you need to provide an object with the "value" field set to the email address. Here’s the correcte...
Good morning, I'm trying to run: databricks bundle run --debug -t dev integration_tests_job My bundle looks: bundle:
name: x
include:
- ./resources/*.yml
targets:
dev:
mode: development
default: true
workspace:
host: x
r...
Hi @jorperort,
The error message you’re seeing, “no deployment state. Did you forget to run ‘databricks bundle deploy’?”, indicates that the deployment state is missing.
Here are some steps you can take to resolve this issue:
Verify Deploym...
Hi there everyone,We are trying to get hands on Databricks Lakehouse for a prospective client's project.Our Major aim for the project is to Compare Datalakehosue on Databricks and Bigquery Datawarehouse in terms of Costs and time to setup and run que...
Hi @ashraf1395, Comparing Databricks Lakehouse and Google BigQuery is essential to make an informed decision for your project.
Let’s address your questions:
Cluster Configurations for Databricks:
Databricks provide flexibility in configuring com...
Hello,We are currently utilizing an autoloader with file listing mode for a stream, which is experiencing significant latency due to the non-incremental naming of files in the directory—a condition that cannot be altered.In an effort to mitigate this...
@Ulman Before turning on the file notification mode, was your pipeline able to access the same storage location or the one you're using now is new location?Could you please share logs and screenshot of error messages?
Hi,I have configured 20 different workflows in Databricks. All of them configured with job cluster with different name. All 20 workfldows scheduled to run at same time. But even configuring different job cluster in all of them they run sequentially w...
Hi @jainshasha,
Running multiple workflows in parallel with their own job clusters in Databricks can be achieved by following the right configuration.
Let’s explore some options:
Shared Job Clusters:
To optimize resource usage with jobs that orch...
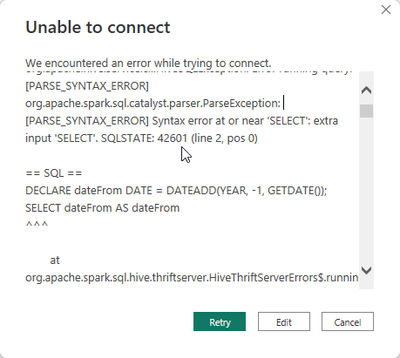
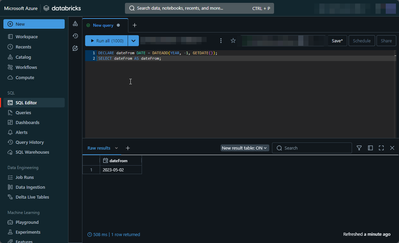
Hello everyone,I'm trying to use the ODBC DirectQuery option in PowerBI, but I keep getting an error about another command. The SQL query works while using the SQL Editor. Do I need to change the setup of my ODBC connector?DECLARE dateFrom DATE = DA...
Hi @mamiya , Here are a few steps you can take to address the error:
Check Power Query Editor Steps:
The error might be related to a specific step in the Power Query Editor. Try opening the Power Query Editor and reviewing the steps. If there’s a...
I have setup my Databricks notebook to use Service Principal to access ADLS using below configuration.service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-accou...
Below is the implementation of same code in scala:spark.sparkContext.hadoopConfiguration.set("fs.azure.account.key.<accountName>.dfs.core.windows.net",<accountKey>)
Hello, I am trying to connect the power bi semantic model output (basically the data that has already been pre processed) to databricks. Does anybody know how to do this? I would like it to be an automated process so I would like to know any way to p...
I need help with migrating from dbfs on databricks to workspace. I am new to databricks and am struggling with what is on the links provided.My workspace.yml also has dbfs hard-coded. Included is a full deployment with great expectations.This was don...
Hi @Ameshj ,
Sorry for the delay in the response.
For the all_df screenshot - how are you creating that df? Does it contain Tablename? How is it related to init script migration?
Kindly add set -x after the first line, and enable cluster logs to DBFS...
Hi @prats33 You can use databricks cluster API for terminate your cluster at any specific time, create notebook for API and schedule it as databricks workflow job on job cluster at 11:59.
Our jobs have been running fine so far w/o any issues on a specific workspace. These jobs read data from files on Azure ADLS storage containers and dont use the hive metastore data at all.Now we attached the unity metastore to this workspace, created...
@Wojciech_BUK Thanks a lot for the feedback! I have a couple of questions: When you say "allow workspace clusters to access storage" - I understand when you talk about interactive cluster. In my case I was trying to trigger a Databricks Notebook/Job ...
Hi,We would like to use Azure Managed Identity to create mount point to read/write data from/to ADLS Gen2?We are also using following code snippet to use MSI authentication to read data from ADLS Gen2 but it is giving error,storage_account_name = "<<...
Hi all,I'm in the progress of migrating from Databricks Azure to Databricks AWS.One part of this is migrating all our workflows which I wanted to via the /api/2.1/jobs/create api with the workflow passed via the json body. I have successfully created...
Hello, many thanks for your question, as per the error message showed it was mentioning a possible timeout or network issue. As first step have you tried to open the page on another browser or using incognito mode?Also have you tried using different ...
I have done the below steps1. Created a databricks managed service principal2. Created a Oauth Secret3. Gave all necessary permissions to the service principalI'm trying to use this Service principal in Azure Devops to automate CI/CD. but it fails as...
Have you follow the steps available for service principal for CI/CD available here: https://learn.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-sp