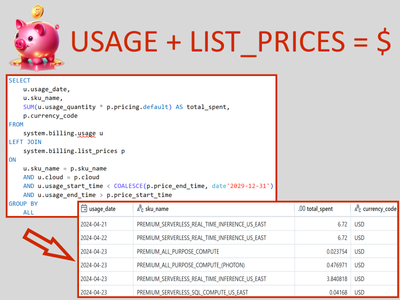
Join two system tables and get exactly how much USD you are spending.The short version of the query: SELECT
u.usage_date,
u.sku_name,
SUM(u.usage_quantity * p.pricing.default) AS total_spent,
p.currency_code
FROM
system.billing....
Parameters can be passed to Tasks and the values can be retrieved with:dbutils.widgets.get("parameter_name")More recently, we have been given the ability to add parameters to Jobs.However, the parameters cannot be retrieved like Task parameters.Quest...
@Kaniz This method works for Task parameters. Is there a way to access Job parameters that apply to the entire workflow, set under a heading like this in the UI:I am able to read Job parameters in a different way from Task parameters using dynamic v...
Hi, Is there any connectivity pipeline established already to access MuleSoft or AnyPoint exchange data using Databricks. I have seen many options to access databricks data in mulesoft but can we read the data from Mulesoft into databricks. Please gi...
I have the following code:spark.sparkContext.setCheckpointDir("dbfs:/mnt/lifestrategy-blob/checkpoints")
result_df.repartitionByRange(200, "IdStation")
result_df_checked = result_df.checkpoint(eager=True)
unique_stations = result_df.select("IdStation...
Thanks a lot for your response. It seems the Filter is not pushed down, no? station_df.explain()
== Physical Plan ==
*(1) Filter (isnotnull(IdStation#2678) AND (IdStation#2678 = 1119844))
+- *(1) Scan ExistingRDD[Date#2718,WindSpeed#2675,Tower_Accele...
When running my notebook using personal compute with instance profile I am indeed able to readStream from kinesis. But adding it as a DLT with UC, while specifying the same instance-profile in the DLT pipeline setting - causes a "MissingAuthenticatio...
Hello,We have unity catalog enabled workspace. To get the completion time of a pipeline that runs multiple times a day, I am checking system.access.audit table. Comparing the completion time of the pipeline compared to other pipeline time I am creat...
I am currently trying to use this feature of "Trigger jobs when new file arrive" in one of my project. I have an s3 bucket in which files are arriving on random days. So I created a job to and set the trigger to "file arrival" type. And within the no...
Looks like a major oversight not to be able to get the information on what file(s) have triggered the job. Anyway, the above explanations given by Anon read like the replies of ChatGPT, especially the scenario where a dataframe is passed to a trigger...
I use AWS Databricks which has an SSO&Scim integration with AAD. I generated an SPN in AAD, synced it to Databricks, and want to use this SPN with using AAD client secrets to use Databricks SDK. But it doesnt work. I dont want to generate another tok...
I have a DLT pipeline, where all tables are non-streaming (materialized views), except for the last one, which needs to be append-only, and is therefore defined as a streaming table.The pipeline runs successfully on the first run. However on the seco...
Hi,I have a DLT pipeline that applies changes from a source table (cdctest_cdc_enriched) to a target table (cdctest), by the following code:dlt.apply_changes( target = "cdctest", source = "cdctest_cdc_enriched", keys = ["ID"], sequence_by...
Hi,I was trying to open the Workflows but there is an error "An error occurred when loading Jobs and Workflows App." we need help to know why it happened and how we can resolve it please.
Same...and the weirdest is that all of the services looks healthy in https://status.databricks.com/Region: eu-central-1Provider: AWSCould anyone provide some info here?
Hi all,I'm in the progress of migrating from Databricks Azure to Databricks AWS.One part of this is migrating all our workflows which I wanted to via the /api/2.1/jobs/create api with the workflow passed via the json body. I have successfully created...
I need to execute a .py file in Databricks from a notebook (with arguments which for simplicity i exclude here). For this i am using:%sh script.pyscript.py:from pyspark import SparkContext
def main():
sc = SparkContext.getOrCreate()
print(sc...
@madrhr
I think this occurs because one session is initiated within the Python script (.py file), while in the Databricks notebook, we have a pre-configured Spark session. It is important to note that we cannot use more than one Spark session per not...
Hello Community Folks -Did anyone implemented migration of notebooks that is in workspace to production databricks workspace using Databricks Asset Bundle? If so can you please help me with any documentation which I can refer? Thanks!!RegardsNiruban ...
Hi everyone!I want to use in-memory cached views in a merge into operation, but I am not entirely sure if the exactly saved in-memory view is used in this operation or not.So, suppose I have a table named table_1 and a cached view named cached_view_1...
@deng_dev - Are you using external metastore by any chance. From the physical plan, we could see the catalog`.`db`.`table_1` is not cached. If it is glue catalog, then caching can be enabled based on the below configs in the article below
https://do...