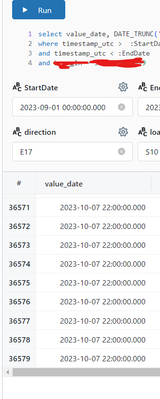
The chunk of code in questionsys.path.append(
spark.conf.get("util_path", "/Workspace/Repos/Production/loch-ness/utils/")
)
from broker_utils import extract_day_with_suffix, proper_case_address_udf, proper_case_last_name_first_udf, proper_case_ud...
Hi @gabe123 , It seems like you’re encountering a ModuleNotFoundError when trying to import the broker_utils module in your Python code.
Let’s troubleshoot this issue step by step:
Check Module Location:
First, ensure that the broker_utils.py fil...
Hello,I am working on a Spark job where I'm reading several tables from PostgreSQL into DataFrames as follows: df = (spark.read
.format("postgresql")
.option("query", query)
.option("host", database_host)
.option("port...
Hi @lieber_augustin, Optimizing the performance of your PostgreSQL queries involves several considerations.
Let’s address both the potential optimizations and the reason behind multiple Scan JDBCRelation operations.
Database Design:
Properly des...
Context:IDE: IntelliJ 2023.3.2Library: databricks-connect 13.3Python: 3.10Description:I develop notebooks and python scripts locally in the IDE and I connect to the spark cluster via databricks-connect for a better developer experience. I download a...
Late to the discussion, but I too was looking for a way to do this _programmatically_, as opposed to the UI.The solution I landed on was using the Python SDK (though you could assuredly do this using an API request instead if you're not in Python):w ...
Hi,I have configured 20 different workflows in Databricks. All of them configured with job cluster with different name. All 20 workfldows scheduled to run at same time. But even configuring different job cluster in all of them they run sequentially w...
Why can I use boto3 to go to secrets manager to retrieve a secret with a personal cluster but I get an error with a shared cluster?NoCredentialsError: Unable to locate credentials
Hey @dbdude, I am facing the same error. Did you find a solution to access the AWS credentials on a Shared Cluster?@Kaniz The reason why fetching the AWS credentials on a Shared Cluster does not work is a limitation of the network and file system acc...
Hello, I am trying to connect the power bi semantic model output (basically the data that has already been pre processed) to databricks. Does anybody know how to do this? I would like it to be an automated process so I would like to know any way to p...
Hi @madhumitha, Connecting Power BI semantic model output to Databricks can be done in a few steps.
Here are a couple of options:
Databricks Power Query Connector:
The new Databricks connector is natively integrated into Power BI. You can configu...
Hello,We are currently utilizing an autoloader with file listing mode for a stream, which is experiencing significant latency due to the non-incremental naming of files in the directory—a condition that cannot be altered.In an effort to mitigate this...
Hi @Ulman ,i think that by default this method will try to create Event Grid and Storage Queue on the same Storage Account as your data.Please not that PREMIUM Blob Storage do not have QUEUE service.In my opinion the easiest way would be to create ma...
Hello, we're working with a serverless SQL cluster to query Delta tables and display some analytics in dashboards. We have some basic group by queries that generate around 36k lines, and they are executed without the "limit" key word. So in the data ...
Hi All,I want to add a member to a group in databricks account level using rest api (https://docs.databricks.com/api/azure/account/accountgroups/patch) as mentioned in this link I could able to authenticate but not able to add member while using belo...
Hi @pragarwal,
The body you’ve shared is almost correct. However, there’s a small issue. Instead of directly providing the email address as the value, you need to provide an object with the "value" field set to the email address. Here’s the correcte...
Good morning, I'm trying to run: databricks bundle run --debug -t dev integration_tests_job My bundle looks: bundle:
name: x
include:
- ./resources/*.yml
targets:
dev:
mode: development
default: true
workspace:
host: x
r...
Hi @jorperort,
The error message you’re seeing, “no deployment state. Did you forget to run ‘databricks bundle deploy’?”, indicates that the deployment state is missing.
Here are some steps you can take to resolve this issue:
Verify Deploym...
Hi there everyone,We are trying to get hands on Databricks Lakehouse for a prospective client's project.Our Major aim for the project is to Compare Datalakehosue on Databricks and Bigquery Datawarehouse in terms of Costs and time to setup and run que...
Hi @ashraf1395, Comparing Databricks Lakehouse and Google BigQuery is essential to make an informed decision for your project.
Let’s address your questions:
Cluster Configurations for Databricks:
Databricks provide flexibility in configuring com...
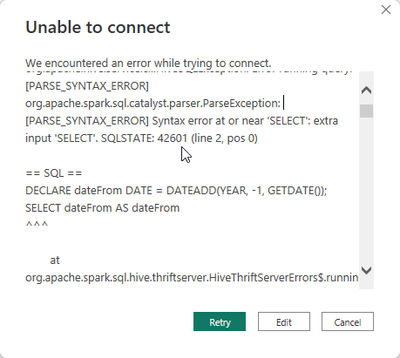
Hello everyone,I'm trying to use the ODBC DirectQuery option in PowerBI, but I keep getting an error about another command. The SQL query works while using the SQL Editor. Do I need to change the setup of my ODBC connector?DECLARE dateFrom DATE = DA...
Hi @mamiya , Here are a few steps you can take to address the error:
Check Power Query Editor Steps:
The error might be related to a specific step in the Power Query Editor. Try opening the Power Query Editor and reviewing the steps. If there’s a...
I have setup my Databricks notebook to use Service Principal to access ADLS using below configuration.service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-accou...
Below is the implementation of same code in scala:spark.sparkContext.hadoopConfiguration.set("fs.azure.account.key.<accountName>.dfs.core.windows.net",<accountKey>)
I need help with migrating from dbfs on databricks to workspace. I am new to databricks and am struggling with what is on the links provided.My workspace.yml also has dbfs hard-coded. Included is a full deployment with great expectations.This was don...
Hi @Ameshj ,
Sorry for the delay in the response.
For the all_df screenshot - how are you creating that df? Does it contain Tablename? How is it related to init script migration?
Kindly add set -x after the first line, and enable cluster logs to DBFS...
Hi @prats33 You can use databricks cluster API for terminate your cluster at any specific time, create notebook for API and schedule it as databricks workflow job on job cluster at 11:59.