Can someone help me by providing steps for creating a new group, as I could not able to find it anywhere? Actually, I wanted to create a new group for Hyderabad, India which I could not able to find in the Groups sections.@Kaniz Fatma @Sujitha Ramam...
I am facing an issue when assign permission on view created on unity catalog. The problem is I had create a user defined function (UDFs) in order to encrypt sensitive column, I create a view which call the functions and source table within the catalo...
I am trying to convert JSON string stored in variable into spark dataframe without specifying schema, because I have a big number of different tables, so it has to be dynamically. I managed to do it with sc.parallelize, but since we are moving to Uni...
Greetings all!I am currently facing an issue while accessing workspace files from the init script.As it was explained in the documentation, it is possible to place init script inside workspace files (link). This works perfectly fine and init script i...
@Gleb Smolnik You might also want to try cloning a github repo in your init script and then storing dependencies like requirements.txt files and other init scripts there. By doing this you can pull a whole slew of init scripts to be utilized in your...
Hi, I recently started learning about spark. I was studying about spark managed tables. so as per docs " spark manages the both the data and metadata". Assume that i have a csv file in s3 and I read it into data frame like below.df = spark.read
.for...
Yes, @Raviiit DBFS (Databricks File System) is a distributed file system used by Databricks clusters. DBFS is an abstraction layer over cloud storage (e.g. S3 or Azure Blob Store), allowing external storage buckets to be mounted as paths in the DBFS ...
i am using dbutils.fs.copy(abfss://container/provsn/filen[ame.txt,abfss://container/data/sasam.txt)while.trying this copy method to copy the files it is showing urisyntax exception near the square bracket how can i read and copy it
From looking at stack trace, it looks like URIException. Easiest solution would be renaming the file so that there are no square brackets in the filename. If this is not an option, it might help to URLEncode the path - https://stackoverflow.com/que...
I have created a Databricks workflow job with notebooks as individual tasks sequentially linked. I assign a value to a variable in one notebook task (ex: batchid = int(time.time()). Now, I want to pass this batchid variable to next notebook task.What...
@brickster You would use dbutils.jobs.taskValues.set() and dbutils.jobs.taskValues.get().See docs for more details: https://docs.databricks.com/workflows/jobs/share-task-context.html
Hello everyone!So I want to ingest tables with schemas from the on-premise SQL server to Databricks Bronze layer with Delta Live Table and I want to do it using Azure Data Factory and I want the load to be a Snapshot batch load, not an incremental lo...
Hi @Parsa Bahraminejad Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best an...
Greetings,I see that Delta Live Tables has various real-time connectors such as Kafka, Kinesis, Google's Pub Sub, and so on. I also see that Apache had maintained an mqtt connector to Spark through the 2.x series called Bahir, but dropped it in versi...
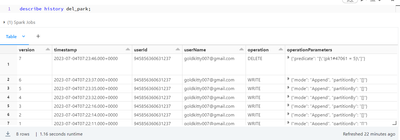
History is piled up as aboveFor testing, I want to erase the history of the table with the VACUUM command."set spark.databricks.delta.retentionDurationCheck.After the option "enabled = False" was given, the command "VACUUM del_park retain 0 hours;" w...
Executing VACUUM performs garbage cleanup on the table directory. By default, a retention threshold of 7 days will be enforced. Please follow the below steps to perform VACCUM: 1.) SET spark.databricks.delta.retentionDurationCheck.enabled false; This...
I am attempting to apply Mosaic's `grid_pointascellid` method on a spark dataframe with `lat`, `lon` columns.```import pyspark.sql.functions as F# Create a Spark DataFrame with a lat and lon columndf = spark.createDataFrame([("point1", 10.0, 20.0),("...
I am applying mosaic's `grid_boundary` method on a spark DataFrame containing a set of `h3_hex_ids`. The geometries returned are not consistent. i.e they could be either `lat, long` or `long, lat`.Here's a sample data```import pyspark.sql.functions a...
It is mentioned in the delta protocol that checkpoints for delta tables are created every 10 commits - however when I modify a table after >10 separate operations (producing >10 separate json files in the _delta_log directory), no checkpoint files ar...
As the latest update now checkpointing of delta tables are created for every 100 commits. This is done for some improvement purpose.If you want to have a checkpoint file for delta table for every 10 commits or after any desired commits. You can cust...
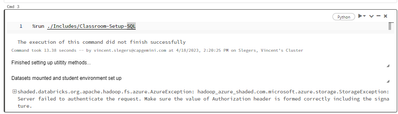
Hello,I found an issue with the Apache Spark™ Programming with Databricks courses on Databricks Academy when trying to do the labs. The mount that the courses use for training data is failing with what looks to me like an authentication issue (see sc...
I found the course Git Repo at (https://github.com/databricks-academy/apache-spark-programming-with-databricks-english), this works so using that instead of the 'apache-spark-programming-with-databricks.dbc' file available in the learning portal. #DA...
I know that UC enabled shared access mode clusters do not allow init script usage and I have tried multiple workarounds to use the required init script in the cluster(pyodbc-install.sh, in my case) including installing the pyodbc package as a workspa...
@Anonymous @Kaniz can anyone form databricks confirm on above issue please, there seems to be bit conflict on using custom scripts support on shared access mode cluster with unity catalog enabled please