I have created a 12.2 LTS cluster and trying to launch notebook attached to this cluster. But unable to launch, it is not giving any error instead it is still showing the same home page.
Hi @Muskan Bansal Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers...
Hi Databricks Community,My Databricks workspace created on Azure pay-as-go subscription.I am facing two sided challenges.First>> I am not able to create Delta-Live-table pipeline or any other all-purpose multi-node cluster as it is throwing below e...
HI All, Thanks for your reply. Just to update you, I am now able to to create DLT pipeline as well as all purpose multi-node cluster with minimum resources. This is due to Quota limit and I was able to increase it. But observation is, if I try to us...
I want to deprecate a query from our workspace. However, I don't know if there is any downstream dashboard needs it.In case there is downstream dependency, then I can't just delete the query.I tried the search by query name, but it only returns the ...
Databricks support suggests me to check the query history, to find out any history of the query, then check which dashboard is using it.Not an ideal solution but it works for me.
In GCP you can give a user access to a view, and then the view itself access to the underlying object, meaning you don't have to give end users access to the tables themselves.Is there a similar way of managing these permissions in databricks? The vi...
Hi @Nick Hughes, Yes, in Databricks, you can also manage permissions at the database and table/view level to grant or revoke access to users or groups.You can create a view in Databricks using the CREATE VIEW command and then grant appropriate permi...
Hello, We have been testing for a long time with Databricks and are now going to run it in production. Our tests were done over Databricks for AWS using the Standard plan and have since upgraded to the Premium plan. One of the aims to upgrade plans w...
Hello, Does anyone have a proper way of contacting support ? As explained in some answers on this thread, we aren't able to create a support ticket in the help centre. We have contacted our account executive 10 days ago, to try to understand why we c...
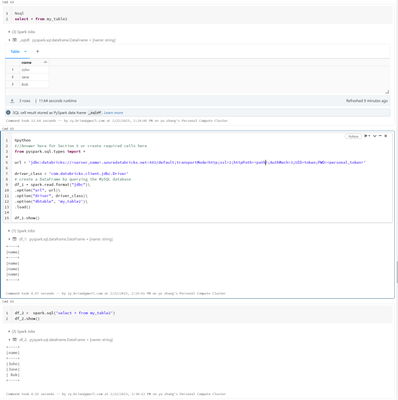
I used code like below to Use JDBC connect to databrick default cluster and read table into pyspark dataframeurl = 'jdbc:databricks://[workspace domain]:443/default;transportMode=http;ssl=1;AuthMech=3;httpPath=[path];AuthMech=3;UID=token;PWD=[your_ac...
@yu zhang :It looks like the issue with the first code snippet you provided is that it is not specifying the correct query to retrieve the data from your database.When using the load() method with the jdbc data source, you need to provide a SQL quer...
I have a bunch of data frames from different data sources. They are all time series data in order of a column timestamp, which is an int32 Unix timestamp. I can join them together by this and another column join_idx which is basically an integer inde...
@Erik Louie :If the data frames have different time zones, you can use Databricks' timezone conversion function to convert them to a common time zone. You can use the from_utc_timestamp or to_utc_timestampfunction to convert the timestamp column to ...
I have a workflow which will run every month and it will create a new notebook containing the outputs from the main notebook. However, after some time, the outputs from the created notebook will disappear. Is there anyway I can retain the outputs?
@Shaun Ang :There are a few possible reasons why the outputs from the created notebook might be disappearing:Notebook permissions: It's possible that the user or service account running the workflow does not have permission to write to the destinati...
I have a column that contains an array of structs as follows:"column" : [
{ "struct_field1": "struct_value", "struct_field2": "struct_value" },
{ "struct_field1": "struct_value", "struct_field2": "struct_value" }
]I want to apply a udf to each f...
Hi @Richard Belihomji, It looks like you are trying to apply a UDF to each field of the structs in an array column in a Spark DataFrame. However, it seems you are encountering an issue with the UDF not receiving the context.To nest a UDF inside a tr...
For an Azure Databricks with vnet injection, we would like to change the networking on the default managed Azure Databricks storage account (dbstorage) from Enabled from all networks to Enabled from selected virtual networks and IP addresses.Can this...
@Sander Sintjorissen usually root storage bucket has below directories present in article https://learn.microsoft.com/en-us/azure/databricks/dbfs/root-locationsto store logs related to auditing you can create another storage and add that. hope this ...
"Apache Spark programming with databricks" tutorial uses Blob storage parquet files on Azure. To access those files a sas key is used in the configuration files. Those keys were generated 5 years ago, however they expired in the begining of this mont...
When connecting to aws s3 bucket using dbfs, application throws error like org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 7864387.0 failed 4 times, most recent failure: Lost task 0.3 in stage 7864387.0 (TID 1709732...
Hi @Amrendra Kumar Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us s...
spark.sql("CREATE TABLE integrated.TrailingWeeks(ID bigint GENERATED BY DEFAULT AS IDENTITY (START WITH 0 increment by 1) ,Week_ID int NOT NULL) USING delta OPTIONS (path 'dbfs:/<Path in Azure datalake>/delta')")
Hi @Shubhendu Das, Thank you for contacting us about your concern about the identity column values in your Databricks Delta table. I understand the deals are not starting at 0 or incrementing by one as expected.Databricks Delta Lake does not guarant...