I have a process which loads data from json to a bronze table. It then adds a couple of columns and creates a silver table. But the silver table has NULL values where there were values in the bronze tables. Process as follows:def load_to_silver(sourc...
@Rachel Cunningham :One possible reason for this issue could be a data type mismatch between the bronze and silver tables. It is possible that the column in the bronze table has a non-null value, but the data type of that column is different from th...
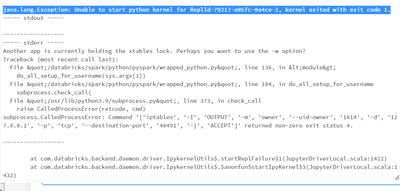
I am running a parameterized autoloader notebook in a workflow.This notebook is being called 29 times in parallel, and FYI UC is also enabled.I am facing this error:java.lang.Exception: Unable to start python kernel for ReplId-79217-e05fc-0a4ce-2, ke...
@Harsh Paliwal :The error message suggests that there might be a conflict with the xtables lock.One thing you could try is to add the -w option as suggested by the error message. You can add the following command to the beginning of your notebook t...
When I run the simple test in a notebook, it works fine, but when I run it from the Azure ADO pipeline, it fails with the error.code;def __init__(self): NutterFixture.__init__(self) from runtime.nutterfixture import NutterFixture, tagclass uTestsDa...
@Chris Konsur :The error message suggests that there is an issue with the standard output buffer when the Python interpreter is shutting down, which could be related to daemon threads. This error is not specific to Databricks or Azure ADO pipeline, ...
when I call RDD Apis during pytest, it seems like module "serializer.py" cannot find any other modules under pyspark.I've already looked up on the internet, and it seems like pyspark modules are not properly importing other referring modules.I see ot...
@hyunho lee : It sounds like you are encountering an issue with PySpark's serializer not being able to find the necessary modules during testing with Pytest. One solution you could try is to set the PYTHONPATH environment variable to include the pat...
Since I am porting some code from Oracle to Databricks, I have another specific question.In Oracle there's something called Virtual Private Database, VPD. It's a simple security feature used to generate a WHERE-clause which the system will add to a u...
@Roger Bieri :In Databricks, you can use the UserDefinedFunction (UDF) feature to create a custom function that will be applied to a DataFrame. You can use this feature to add a WHERE clause to a DataFrame based on the user context. Here's an exampl...
Tree-based estimators in pyspark.ml have an argument called checkpointIntervalcheckpointInterval = Param(parent='undefined', name='checkpointInterval', doc='set checkpoint interval (>= 1) or disable checkpoint (-1). E.g. 10 means that the cache will ...
@Federico Trifoglio :If sc.getCheckpointDir() returns None, it means that no checkpoint directory is set in the SparkContext. In this case, the checkpointInterval argument will indeed be ignored. To set a checkpoint directory, you can use the SparkC...
@Janga Reddy :Certainly! Here are the steps for Hive metastore backup and restore on Databricks:Backup:Stop all running Hive services and jobs on the Databricks cluster.Create a backup directory in DBFS (Databricks File System) where the metadata fi...
Hello dear community,we have installed a custom spark extension to filter the files allowed to be read into the notebook. It was all good if we use the spark functions.However, the files are not filtered properly if the user would use e.g., dbutils.f...
Hi @Yuan Gao,Checking in. If @tayyab vohra's answer helped, would you let us know and mark the answer as best? If not, would you be happy to give us more information? Thanks!
Hi,there was a need to query an older snapshot of a table. Therefore ran:deltaTable = DeltaTable.forPath(spark, 'dbfs:/<path>') display(deltaTable.history())and noticed that every fs.write_table run triggers two operations:Write and CREATE OR REPLACE...
@Direo Direo :When you use deltaTable.write() method to write a DataFrame into a Delta table, it actually triggers the Delta write operation internally. This operation performs two actions:It writes the new data to disk in the Delta format, andIt at...
Hi All,I was trying to setup Security Analysis Tool (SAT) on Azure Databricks cluster. I followed the setup steps motioned over here - https://github.com/databricks-industry-solutions/security-analysis-tool/blob/main/docs/setup.mdI started to run "se...
For those who may be coming here to this questions, thanks to @Arnold Souza and @Harish Koduru We not only updated our setup instructions https://github.com/databricks-industry-solutions/security-analysis-tool/blob/main/docs/setup.md but we also c...
java.util.concurrent.TimeoutException: Futures timed out after [5 seconds] at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:259) at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:263) at scala.concurrent.Await$.$...
Hi @Mahesh Chahare Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us s...
I have folder structure at source such as/transaction/date_=2023-01-20/hr_=02/tras01.csv/transaction/date_=2023-01-20/hr_=03/tras02.csvWhere 'date_' and 'hr_' are my partitions and present in the dataset as well. But the streamReader does not read th...
Hi @Ravi Vishwakarma Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answ...
Hi @z yang Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your q...
We're using a setup where we use gitlab ci to deploy workflows using a service principal, using the Jobs API (2.1) https://docs.databricks.com/dev-tools/api/latest/jobs.html#operation/JobsCreateWhen we wanted to reduce permissions of the ci to minimu...
Hi @Geir Iversen Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers ...
We have a Cursor in DB2 which reads in each loop data from 2 tables. At the end of each loop, after inserting the data to a target table, we update records related to each loop in these 2 tables before moving to the next loop. An indicative example i...
Hi @ELENI GEORGOUSI Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answe...