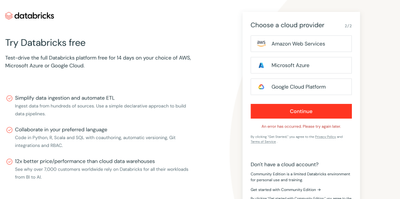
I've been trying to create Community Edition account, but keep getting: "An error has occurred. Please try again later" message. I searched the other posts, there are some people running into the same issue as well, but don't see any solution posted....
Hi @Liang He Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
I successfully built a custom docker image for the Standard runtime following the steps described on the page Customize containers with Databricks Container Services and based on the image databricksruntime/standard:11.3-LTS. However, I cannot find ...
Hi @Tibor Fabian Help us build a vibrant and resourceful community by recognizing and highlighting insightful contributions. Mark the best answers and show your appreciation!
I am using Autoloader to load files from a directory. I have set up File Notification with the Event Subscription. I have a backfill interval set to 1 day and have not run the stream for a week. There should only be about ~100 new files to pick up an...
Hi @nolanlavender008 Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answ...
Hi All,Many users already posted about this but no action taken till now., i tried to use different browsers and system still not able to maximize the spark training videos.Many months passed still databricks people are not correcting this mistake. @...
Hi @Abhishek Joshi Help us build a vibrant and resourceful community by recognizing and highlighting insightful contributions. Mark the best answers and show your appreciation!
I have a big data delta table with timestamp, key and metric(s) columns (e.g. m1, m2, ...).I often will group by the key (e.g. select max(m1) group by timestamp, key).I cannot partition by `key` because there are too many values( ~200K).I have tried ...
Hi @Hanan Shteingart Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...
Hi all we are trying to do cosmos patch api to a array field but the problem I see is we need to collect the data to get the index can you please let us know if we have an alternative as this causes bottleneck on driver
Hi @somanath Sankaran Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your fee...
how to guarantee the index is always following the file's original order no matter what. Currently, I'm using val df = spark.read.options(Map("header"-> "true", "inferSchema" -> "true")).csv("filePath").withColumn("index", monotonically_increasing...
monotonically_increasing_id will not as it is to guarantee that every partition has separate ids. What is the whole code? Do you load directory with a lot of CSVs? What "original order" means? Is it csvs ordered by file creation date, by file name? o...
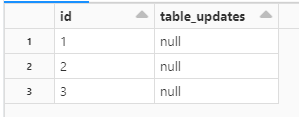
I have a delta table created by:%sql
CREATE TABLE IF NOT EXISTS dev.bronze.test_map (
id INT,
table_updates MAP<STRING, TIMESTAMP>,
CONSTRAINT test_map_pk PRIMARY KEY(id)
) USING DELTA
LOCATION "abfss://bronze@Table Path"With initi...
Hi @Mohammad Saber Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedba...
I am reading a 83MB json file using " spark.read.json(storage_path)", when I display the data is seems displaying fine, but when I try command line count, it complains about file size , being more than 400MB, which is not true.Photon JSON reader erro...
@Kamal Kumar :The error message suggests that the JSON document size is exceeding the maximum allowed size of 400MB. This could be caused by one or more documents in your JSON file being larger than this limit. It is not a bug, but a limitation set ...
@Lukas Goldschmied :There are a few reasons why you might be experiencing this issue:Data Skew: Data skew is a common problem in distributed computing when one or more nodes in the cluster have more data to process than others. This can lead to long...
I have spent way too much time to find a solution to the problem of efficiently writing data to Databricks via JDBC/ODBC. I have looked into countless docs, blogs and repos and I cannot find one example where someone is setting some kind of batch/bul...
Hi Team,I have completed the fundamentals of databricks lakehouse platform and received the certificate but unable to download or get the badge.When I login to website I am unbale to see the badge as well.Please help me on this.I haven't received any...
Hi @Nupur Dogra Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so w...
I have attended an event on certification preparation on databricks data engineer associate on 17th Jan 2023.I have filled the survey form and it was mentioned that I will receive the voucher in early Feb.Still I have not received.Please update me as...
Hi @Rituparna Das Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so...
How to approach the databricks team if we facing any problem Some time question is not appearing properly so any one know the solution kindly tell me
Hi @S Meghala Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we ...
Hi @Krishnamoorthy Natarajan Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Y...