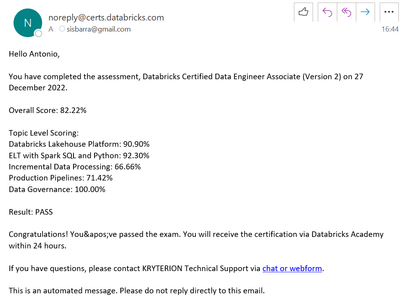
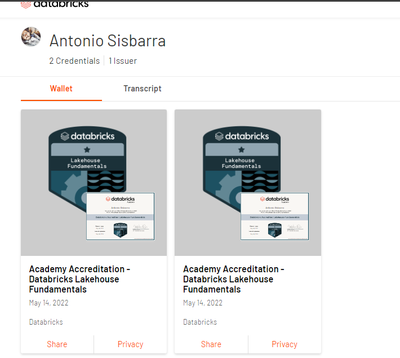
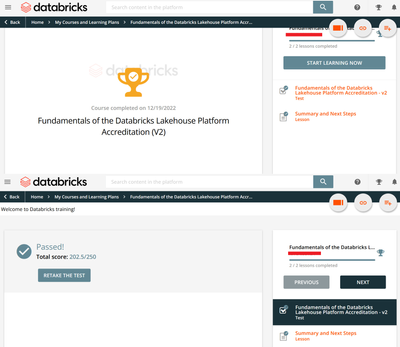
Hi all,today (27/12/22 14:00 Rome Time Zone) I passed the Data Engineer Associate exam, but I received the badge of Lakehouse Fundamentals (second time). My email address is: sisbarra@gmail.comMy company address is: antonio.sisbarra@nttdata.comCan ...
Hello, this is regarding Databricks Lakehouse Fundamentals Accreditation V2. I haven't received my badge/certificate. I also raised a ticket but haven't received any response. My request id is #00248504.. Kindly help me out with this.
@Jose Gonzalez ,@Vidula Khanna ,I also did not received my badge in portalThis is my portal link- https://credentials.databricks.com/profile/aviralbhardwaj143185/walletMy case number is - 00250939Also, my points are not updating in the reward port...
Hi Team,I am trying to configure access to adls through Service Principal through Spark Config in Databricks job cluster. like, fs.azure.account.oauth2.client.id.<adls_account_name>.dfs.core.windows.net {{secrets/scopeName/clientID}}The above stateme...
Hi, I see the option for "Full screen" on bottom right but its disabled/inactive. Attached is the screenshot for same.Please advise as its hard to read or see contents on half screen.Thanks
Looks like it is because the oauth2client.service_account does not know about DBFS (whereas spark does).Is it an option to manage your secrets in databricks? https://docs.databricks.com/security/secrets/secrets.html
We moved in Databricks since few months from now, and before that we were in SQL Server.So, all our tables and databases follow the "camel case" rule.Apparently, in Databricks the rule is "lower case with underscore".Where can we find an official doc...
Hi @Salah KHALFALLAH , looking at the documentation it appears that Databricks' preferred naming convention is lowercase and underscores as you mentioned.The reason for this is most likely because Databricks uses Hive Metastore, which is case insens...
i am reading data from IBM DB2 and saving into a MS SQL server (the first step is moving the code itself to databricks, and then we will move the databases to databricks itself). Problem I'm running into is doing something like the below will take > ...
Hi, it is related to partitioning optimization. By default, the JDBC driver queries the source database with only a single thread. So write was from one partition as one partition was created, so it was using a single core. When you used pandas, it d...
Is anybody actually using the RStudio app integration on Databricks? I'm surprised to find so little discussion in this forum. My team has been using it for about 3 months and it seems under-developed.1) No automated backup, you have to do it yoursel...
@Jonathan Dufault Thanks for the response, and glad I'm not alone. My problem (and this is probably just a preference thing) is that the 'reward' of using a full-fledged IDE is huge, compared to bouncing between notebooks in multiple tabs. The integ...
Singleton Design Principle for pyspark database connectorA singleton is a design pattern that ensures that a class has only one instance, and provides a global access point to that instance. Here is an example of how you could implement a singleton d...
I'm looking for direction on how to get the dbt task in workflows to use the partial_parse.msgpack file to skip parsing files that haven't changed. I'm downloading my artifacts after each run and the partial_parse file is being saved back to adls.Wha...
Hi. I assume that it can be concurrency issue. (a Read thread from Databricks and a Write thread from another system)From the start:I read 12-16 csv files (approximately 250Mb each of them) to dataframe. df = spark.read.option("header", "False").opti...
Hi @Anastasiia Polianska,I agree, it looks like a concurrency issue. Very possibly this concurrency problem will be caused by an erroneous ETAG in the HTTP call to the Azure Storage API (https://azure.microsoft.com/de-de/blog/managing-concurrency-in...
Hi @maddy v ,I recommend that you use the Databricks SQL module for this type of reports and email alerts. It is a very interesting module with multiple options for your use case.https://learn.microsoft.com/en-us/azure/databricks/sql/user/dashboards...
I am using Spark SQL to import their data into a machine learning pipeline. Once data is imported I want performs machine learning tasks using Spark ML. So I should use what compute tools is best suited for this use case? Please help me!!! Thank you ...