Hi Team, I am writing a python code in Azure Databricks where I have mounted a Azure storage and accessing the input dataset from Azure storage resource. I am accessing the input data from Azure storage and generating charts from that data in databri...
Hi @Abhishek Jain Thanks for sending in your query. We are glad that you found a solution. Would you like to mark the answer as best so the other members can benefit from it too?Cheers!
Hi everyone,We are looking for a way to protect the folder where init script is hosted from editing.This because we have implemented inside init script a parameter that blocks the download file from R Studio APP Emulator and we would like to avoid th...
Hi @Marco Data Thank you for sending in your question. It is awesome that you found a solution. Would you like to mark the answer as best so others can find the solution quickly?Cheers!
In my Azure Databricks workspace UI I do not have the tab "Delta live tables". In the documentation it says that there is a tab after clicking on Jobs in the main menu. I just created this Databricks resource in Azure and from my understanding the DL...
Hi Everyone / Experts,is it possible to use Delta Tables without the Time Travel features? We are primarily interested in using the DML Features (delete, update, merge into, etc)Thanks,Mark
I have python variable created under %python in my jupyter notebook file in Azure Databricks. How can I access the same variable to make comparisons under %sql. Below is the example:%python
RunID_Goal = sqlContext.sql("SELECT CONCAT(SUBSTRING(RunID,...
You can use {} in spark.sql() of pyspark/scala instead of making a sql cell using %sql.This will result in a dataframe. If you want you can create a view on top of this using createOrReplaceTempView()Below is an example to use a variable:-# A variab...
Hi databricks experts. I am currently facing a problem with a submitted job run on Azure Databricks. Any help on this is very welcome. See below for details:Problem Description:I submitted a python spark task via the databricks cli (v0.16.4) to Azure...
Last week, I cannot loginto https://community.cloud.databricks.com/login.html all of a sudden. I tried to set the password, also didn't receive the reset email. It says "Invalid email address or password Note: Emails/usernames are case-sensitive".I e...
Dear connections,I'm unable to run a shell script which contains scheduling a Cron job through init script method on Azure Data bricks cluster nodes.Error from Azure Data bricks workspace:"databricks_error_message": "Cluster scoped init script dbfs:/...
Hello @Sugumar Srinivasan Could you please enable cluster log delivery and inspect the INIT script logs in the below path dbfs:/cluster-logs/<clusterId>/init_scripts path.https://docs.databricks.com/clusters/configure.html#cluster-log-delivery-1
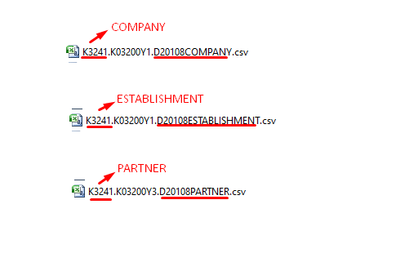
Hello everyone, I have a directory with 40 files.File names are divided into prefixes. I need to rename the prefix k3241 according to the name in the last prefix.I even managed to insert the csv extension at the end of the file. but renaming files ba...
Hi @welder martins How are you doing?Thank you for posting that question. We are glad you could resolve the issue. Would you want to mark an answer as the best solution?Cheers
Greetings,I have been reading the excellent article from https://docs.databricks.com/security/privacy/gdpr-delta.html?_ga=2.130942095.1400636634.1649068106-1416403472.1644480995&_gac=1.24792648.1647880283.CjwKCAjwxOCRBhA8EiwA0X8hi4Jsx2PulVs_FGMBdByBk...
@Hubert Dudek thanks for the hint, exactly as written in the article VACUUM is required after the GDPR delete operation, however do we need to OPTIMIZE ZSORT again the table or is the ordering maintained?
I write data to s3 like data.write.format("delta").mode("append").option("mergeSchema", "true").save(s3_location)and create a partitioned table likeCREATE TABLE IF NOT EXISTS demo_table
USING DELTA
PARTITIONED BY (column_a)
LOCATION {s3_location};whi...
I have data in a Spark Dataframe and I write it to an s3 location. It has some complex datatypes like structs etc. When I create the table on top on the s3 location by using CREATE TABLE IF NOT EXISTS table_name
USING DELTA
LOCATION 's3://.../...';Th...
Hi Can you help me why Pandas code not working..but Pyspark is working..import pandas as pdpdf = pd.read_csv('/FileStore/tables/new.csv',sep=',')Error : No such file exists...below is worked..df = spark.read.csv("/FileStore/tables/new.csv", sep=",", ...
Hi @Rafael Rockenbach and @Hubert Dudek , It was so nice to have your response. Thank you for the time you put into our community. I really want you to know how much we appreciate that.
Hey all-I have a python script running in databricks notebook which uses smtplib to connect and send email via our Exchange online server. At random times, it will start getting authentication failures and I can't figure out why. I've confirmed that ...
the delta tables after ETL are stored in s3 in csv or parquet format, so now question is how to allow databricks sql endpoint to run query over s3 saved files