Hi Guys. I have looked at the formatting options and I'm still struggling to work out how to best format the email body of a databricks alert. I want to be able to selectively choose columns from the query and dispaly them in a table. Or even if i ca...
Hi @Nick Hughes , unfortunately, this is not available for now. We have a feature request for the same. DB-I-4105 - SQL Alerts: Formatting message body when creating Custom TemplateThis feature has been considered by our product team and it will be...
"If a cluster is created from a pool, its EC2 instances inherit only the custom and default pool tags, not the cluster tags. Therefore if you want to create clusters from a pool, make sure to assign all of the custom cluster tags you need to the pool...
Good day, Copy of https://stackoverflow.com/questions/69974301/looping-through-files-in-databricks-failsI got 100 files of csv data on adls-gen1 store. I want to do some processing to them and save results to same drive, different directory. def look...
was actually anything created by script in directory <my_output_dir>?The best would be to permanently mount ADSL storage and use azure app for that.In Azure please go to App registrations - register app with name for example "databricks_mount" . Ad...
hi @SEBIN THOMAS ,I would like to share the docs here are you getting any error messages? like @Hubert Dudek mentioned, please share more details and error message in case you are getting any.
I have a customer with the following question - I'm posting on their behalf to introduce them to the community. For doing modeling in a python environment what is our best practice for getting the data from redshift? A "load" option seems to leave me...
For context, I am running Spark on databricks platform and using Delta Tables (s3). Let's assume we a table called table_one. I create a view called view_one using the table and then call view_one. Next, I create another view, called view_two based o...
Hi @John Constantine ,The following notebook url will help you to undertand better the difference between lazy transformations and action in Spark. You will be able to compare the physical query plans and undertand better what is going on when you e...
Hi, I would like to import a python file to Databricks with a Azure DevOps Release Pipeline.Within the pipeline I execute a python script which contains this code :import sys
import os
import base64
import requests
dbw_url = sys.argv[1] # https://a...
Recently I wrote about alternative way to export/import notebooks in pthon https://community.databricks.com/s/question/0D53f00001TgT52CAF/import-notebook-with-python-script-using-api This way you will get more readable error/message (often it is rela...
Does anyone know alternative for AWS Macie in Azure?AWS Macie scan S3 buckets for files with sensitive data (personal address, credit card etc...).I would like to use the same style ready scanner for Azure Data Lake.
Hi @ahana ahana ,Did any of the replies helped you solve this issue? would you be happy to mark their answer as best so that others can quickly find the solution?Thank you
Hi @Christopher Shehu , if @Piper Wilson 's response helped you to solve your question? would you be happy to mark her answer as best so that others can quickly find the solution in the future.
Hello guys.I'm trying to read JSON file which contains backslash and failed to read it via pyspark.Tried a lot of options but didn't solve this yet, I thought to read all the JSON as text and replace all "\" with "/" but pyspark fail to read it as te...
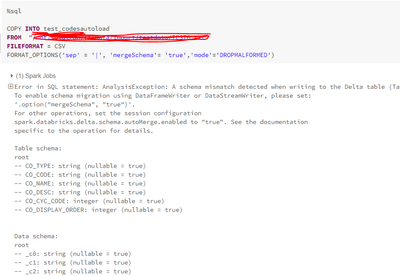
Hi All,I am trying to read a csv file from datalake and loading data into sql table using Copyinto.am facing an issue Here i created one table with 6 columns same as data in csv file.but unable to load the data.can anyone helpme on this
I'm using the logging module to log the events from the job, but it seems the log is creating the file with only 1 lines. The consecutive log events are not being recorded. Is there any reference for custom logging in Databricks.
@karthick J - If Jose's answer helped solve the issue, would you be happy to mark their answer as best so that others can find the solution more easily?
I have a notebook with many join and few persist operations (which runs fine on all-purpose-cluster (with worker nodes - i3.xlarge and autoscale enabled), but the same notebook failing in job-cluster with the same cluster definition (to be frank the ...
Hi @Ajay Nanjundappa ,Check "Event log" tab. Search for any spot terminations events. It seems like all your nodes are spot instances. The error "FetchFailedException" is associated with spot termination nodes.
@Mohit Miglani ,Make sure to select the best option so the post will be moved to the top and will help in case more users have this question in the future.