- 1063 Views
- 1 replies
- 2 kudos
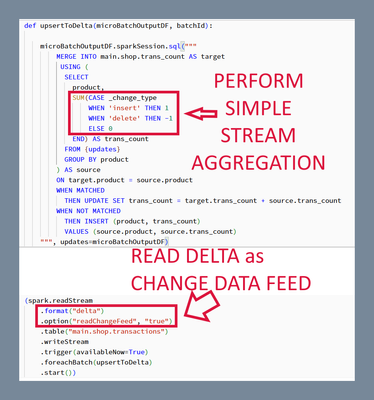
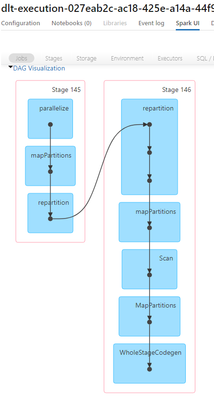
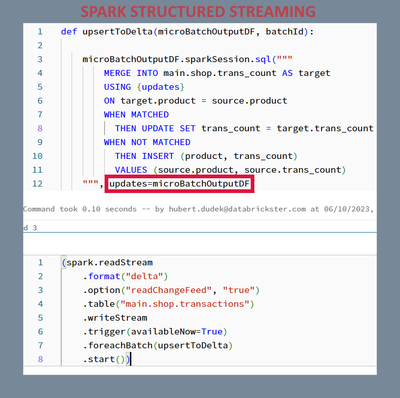
foreachBatch
With parameterized SQL queries in Structured Streaming's foreachBatch, there's no longer a need to create temp views for the MERGE command.
- 1063 Views
- 1 replies
- 2 kudos
Latest Reply
- 2 kudos
Thank you for sharing the valuable information @Hubert-Dudek
- 2 kudos